Fused-Planes: Why Train a Thousand Tri-Planes When You Can Share?
Karim Kassab ⋅ Antoine Schnepf ⋅ Jean-Yves Franceschi ⋅ Laurent Caraffa ⋅ Flavian Vasile ⋅ Jeremie Mary ⋅ Andrew Comport ⋅ Valerie Gouet-Brunet
{kind=link}
Abstract
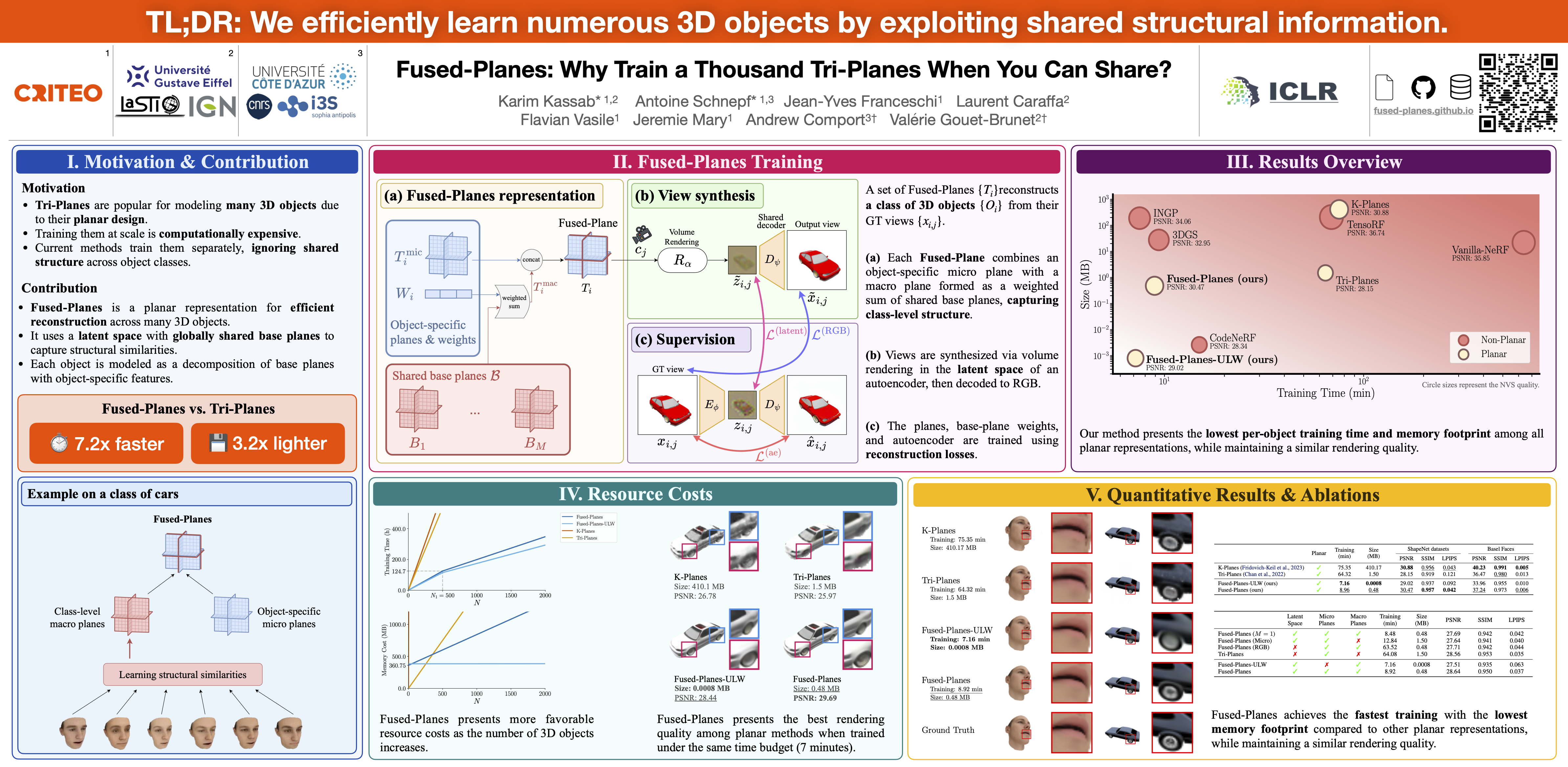
Tri-Planar NeRFs enable the application of powerful 2D vision models for 3D tasks, by representing 3D objects using 2D planar structures. This has made them the prevailing choice to model large collections of 3D objects. However, training Tri-Planes to model such large collections is computationally intensive and remains largely inefficient. This is because the current approaches independently train one Tri-Plane per object, hence overlooking structural similarities in large classes of objects. In response to this issue, we introduce Fused-Planes, a novel object representation that improves the resource efficiency of Tri-Planes when reconstructing object classes, all while retaining the same planar structure. Our approach explicitly captures structural similarities across objects through a latent space and a set of globally shared base planes. Each individual Fused-Planes is then represented as a decomposition over these base planes, augmented with object-specific features. Fused-Planes showcase state-of-the-art efficiency among planar representations, demonstrating $7.2 \times$ faster training and $3.2 \times$ lower memory footprint than Tri-Planes while maintaining rendering quality. An ultra-lightweight variant further cuts per-object memory usage by $1875 \times$ with minimal quality loss. Our project page can be found at https://fused-planes.github.io .
Video
Chat is not available.
Successful Page Load