SimpleGVR: A Simple Baseline for Latent-Cascaded Generative Video Super-Resolution
{kind=link}
Abstract
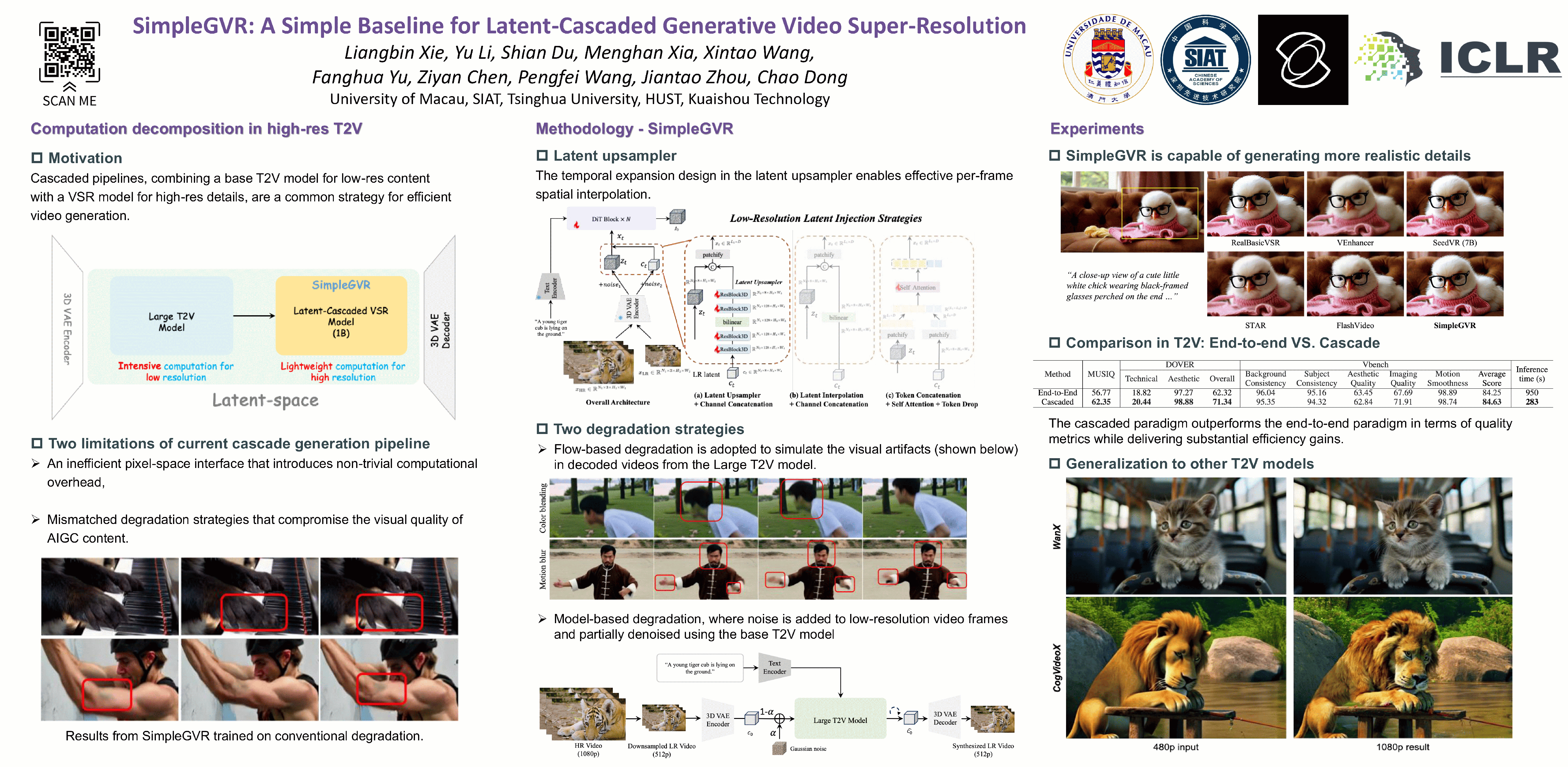
Cascaded pipelines, which use a base text-to-video (T2V) model for low-resolution content and a video super-resolution (VSR) model for high-resolution details, are a prevailing strategy for efficient video synthesis. However, current works suffer from two key limitations: an inefficient pixel-space interface that introduces non-trivial computational overhead, and mismatched degradation strategies that compromise the visual quality of AIGC content. To address these issues, we introduce SimpleGVR, a lightweight VSR model designed to operate entirely within the latent space. Key to SimpleGVR are a latent upsampler for effective, detail-preserving conditioning of the high-resolution synthesis, and two degradation strategies (flow-based and model-guided) to ensure better alignment with the upstream T2V model. To further enhance the performance and practical applicability of SimpleGVR, we introduce a set of crucial training optimizations: a detail-aware timestep sampler, a suitable noise augmentation range, and an efficient interleaving temporal unit mechanism for long-video handling. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded systems. Video visual comparisons are available at https://simplegvr.github.io/.