EdiVal-Agent: An Object-Centric Framework for Automated, Fine-Grained Evaluation of Multi-Turn Editing
{kind=link}
Abstract
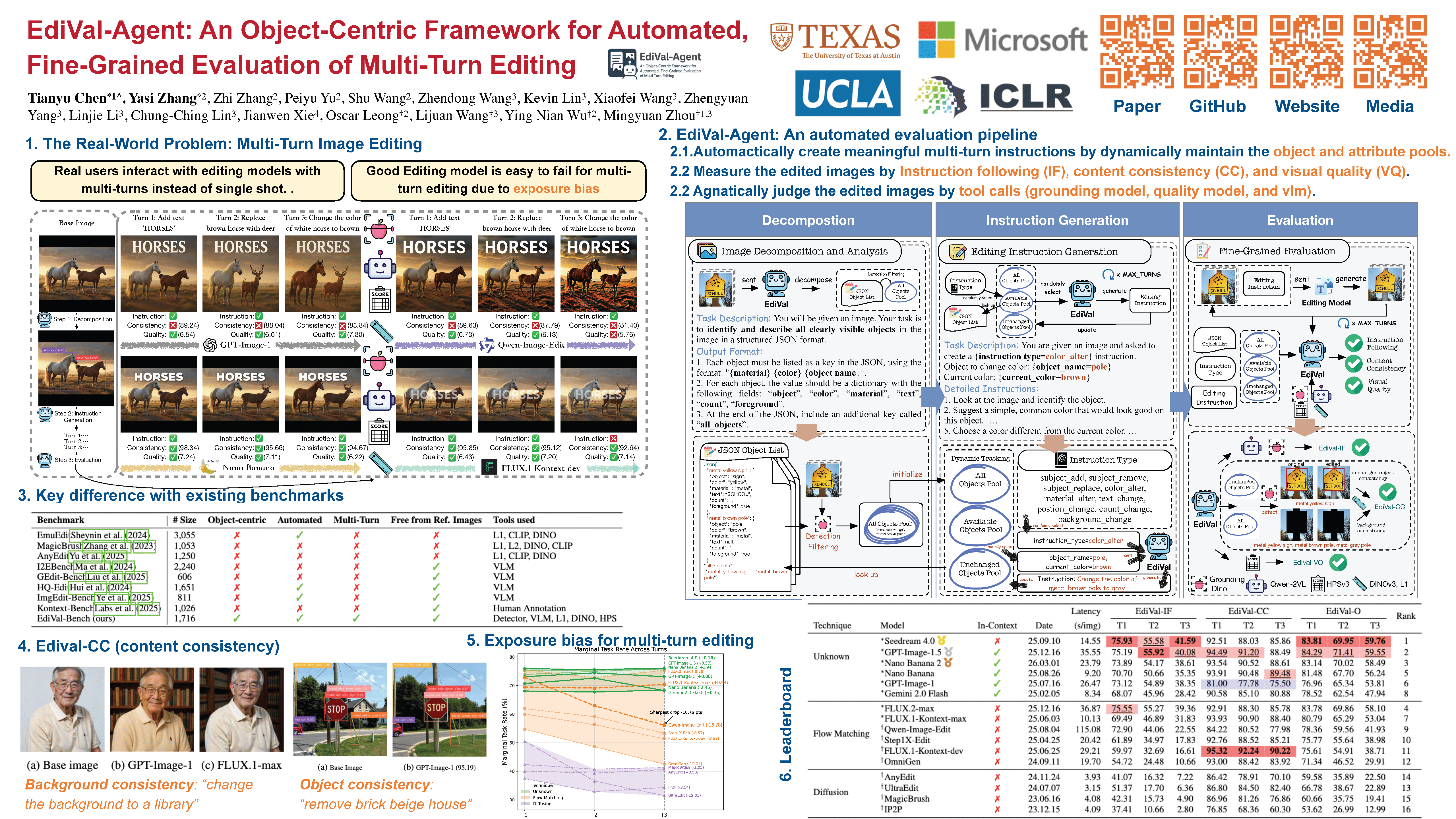
Instruction-based image editing has advanced rapidly, yet reliable and interpretable evaluation remains a bottleneck. Current protocols either (i) depend on paired reference images—resulting in limited coverage and inheriting biases from prior generative models—or (ii) rely solely on zero-shot vision–language models (VLMs), whose prompt-based assessments of instruction following, content consistency, and visual quality are often imprecise. To address this, we introduce EdiVal-Agent , an automated and fine-grained evaluation framework grounded in an object-centric perspective, designed to assess not only standard single-turn but also multi-turn instruction-based editing with precision. Given an input image, EdiVal-Agent first decomposes it into semantically meaningful objects, then synthesizes diverse, context-aware editing instructions while dynamically updating object pools across turns. These two stages enable two novel object-centric metrics tailored for multi-turn evaluation and one global metric of visual quality: 1) EdiVal-IF, which measures instruction following by combining open-vocabulary object detectors for symbolic checks with VLMs for semantic verification on detector-guided crops; 2) EdiVal-CC, which evaluates content consistency by calculating semantic similarity of unchanged objects and background using the evolving object pools; and 3) EdiVal-VQ, which quantifies changes in overall visual quality with human preference models. Instantiating this pipeline, we build EdiVal-Bench, a multi-turn editing benchmark covering 9 instruction types and 16 state-of-the-art editing models spanning in-context, flow-matching, and diffusion paradigms. Our results show that Seedream 4.0 achieves the best overall performance, offering the strongest balance of instruction following, content consistency, and latency. GPT-Image-1.5 clearly improves over GPT-Image-1, especially in content consistency across turns, while Nano Banana 2 consistently outperforms Nano Banana in instruction following and overall score,. Among flow-matching models, FLUX.2-max is the strongest baseline, whereas Qwen-Image-Edit performs well on the first turn but degrades sharply in later turns, indicating strong exposure bias in multi-turn editing. We demonstrate that EdiVal-Agent can be used to identify existing failure modes, thereby informing the development of the next generation of editing models. Our code is available at https://github.com/TianyuCodings/EdiVal.