How Far Can Unsupervised RLVR Scale LLM Training?
{kind=link}
Abstract
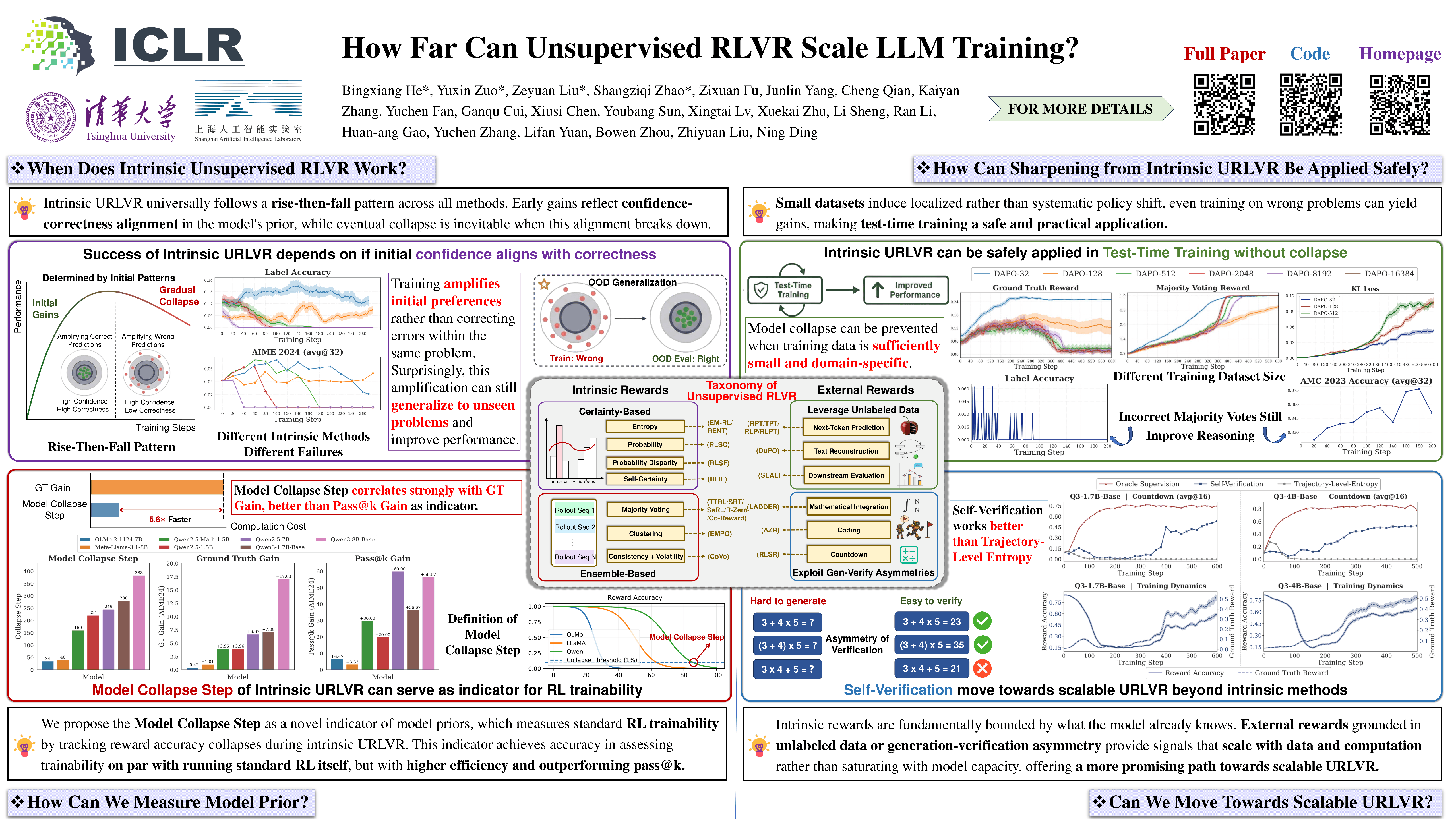
Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives. Code is available at \url{https://github.com/PRIME-RL/TTRL}.