Membership Privacy Risks of Sharpness Aware Minimization
{kind=link}
Abstract
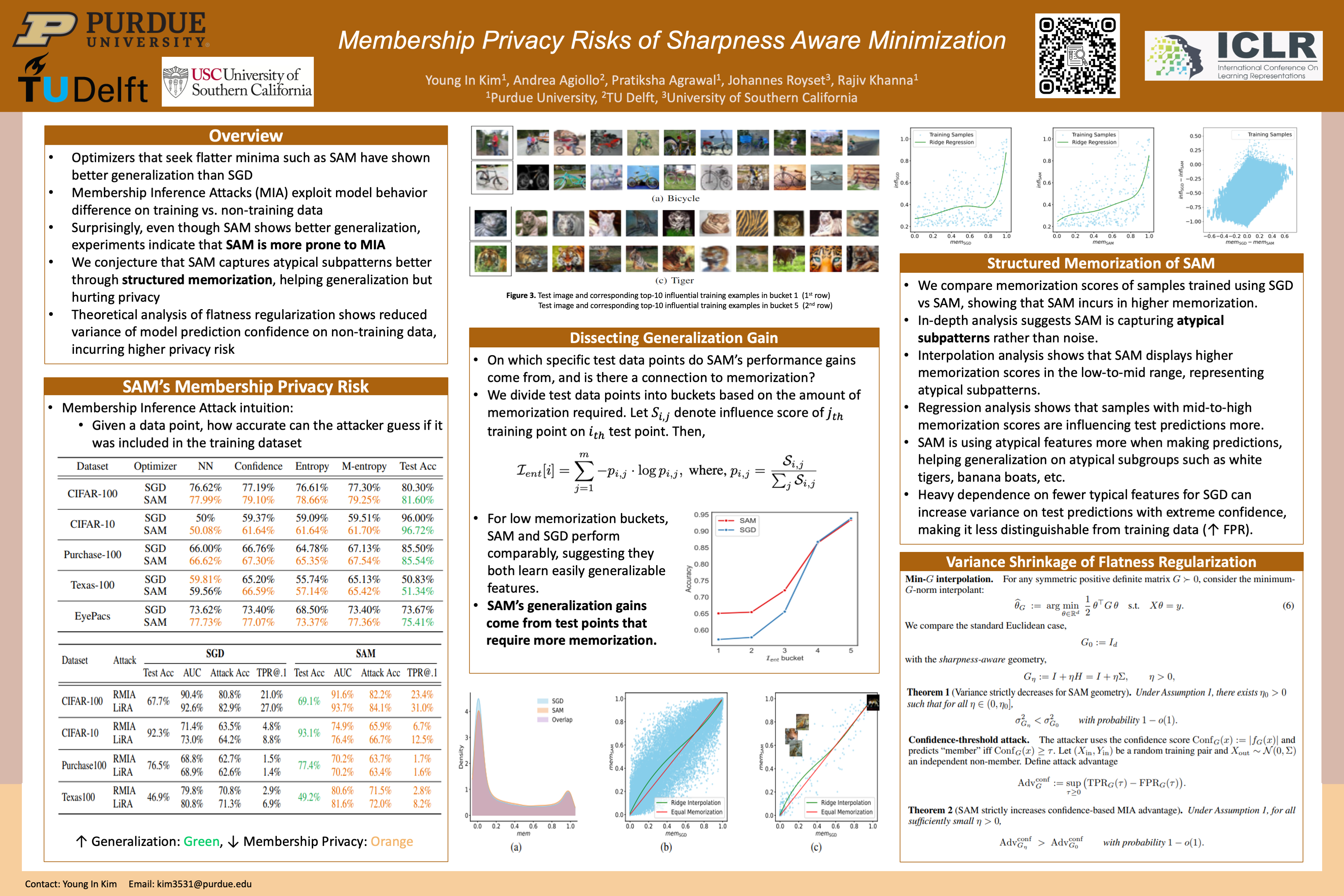
Optimization algorithms that seek flatter minima, such as Sharpness-Aware Minimization (SAM), are credited with improved generalization and robustness to noise. We ask whether such gains impact membership privacy. Surprisingly, we find that SAM is more prone to Membership Inference Attacks (MIA) than classical SGD across multiple datasets and attack methods, despite achieving lower test error. This suggests that the geometric mechanism of SAM that improves generalization simultaneously exacerbates membership leakage. We investigate this phenomenon through extensive analysis of memorization and influence scores. Our results reveal that SAM is more capable of capturing atypical subpatterns, leading to higher memorization scores of samples. Conversely, SGD depends more heavily on majority features, exhibiting worse generalization on atypical subgroups and lower memorization. Crucially, this characteristic of SAM can be linked to lower variance in the prediction confidence of unseen samples, thereby amplifying membership signals. Finally, we model SAM under a perfectly interpolating linear regime and theoretically show that sharpness regularization inherently reduces variance, guaranteeing a higher MIA advantage for confidence and likelihood ratio attacks.