Scaling Attention via Feature Sparsity
Yan Xie ⋅ Tiansheng Wen ⋅ Tang Da Huang ⋅ Bo Chen ⋅ Chenyu You ⋅ Stefanie Jegelka ⋅ Yifei Wang
{kind=link}
Abstract
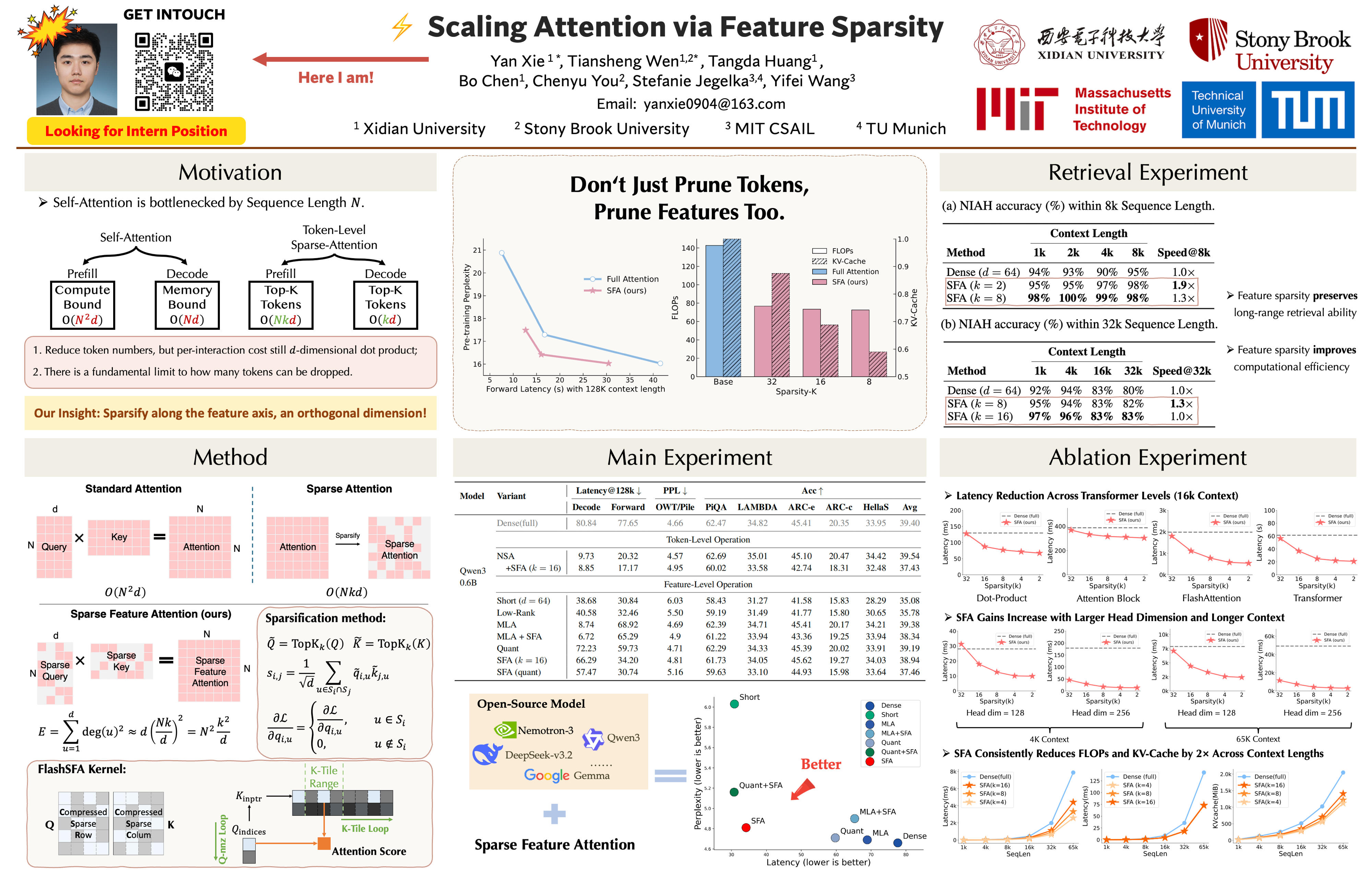
Scaling Transformers to ultra-long contexts is bottlenecked by the $O(n^2 d)$ cost of self-attention. Existing methods reduce this cost along the sequence axis through local windows, kernel approximations, or token-level sparsity, but these approaches consistently degrade accuracy. In this paper, we instead explore an orthogonal axis: \emph{feature sparsity}. We propose \textbf{Sparse Feature Attention (SFA)}, where queries and keys are represented as $k$-sparse codes that preserve high-dimensional expressivity while reducing the cost of attention from $\Theta(n^2 d)$ to $\Theta(n^2 k^2/d)$. To make this efficient at scale, we introduce \textbf{FlashSFA}, an IO-aware kernel that extends FlashAttention to operate directly on sparse overlaps without materializing dense score matrices. Across GPT-2 and Qwen3 pretraining, SFA matches dense baselines while improving speed by up to $2.5\times$ and reducing FLOPs and KV-cache by nearly 50\%. On synthetic and downstream benchmarks, SFA preserves retrieval accuracy and robustness at long contexts, outperforming short-embedding baselines that collapse feature diversity. These results establish feature-level sparsity as a complementary and underexplored axis for efficient attention, enabling Transformers to scale to orders-of-magnitude longer contexts with minimal quality loss.
Video
Chat is not available.
Successful Page Load