Features Emerge as Discrete States: The First Application of SAEs to 3D Representations
{kind=link}
Abstract
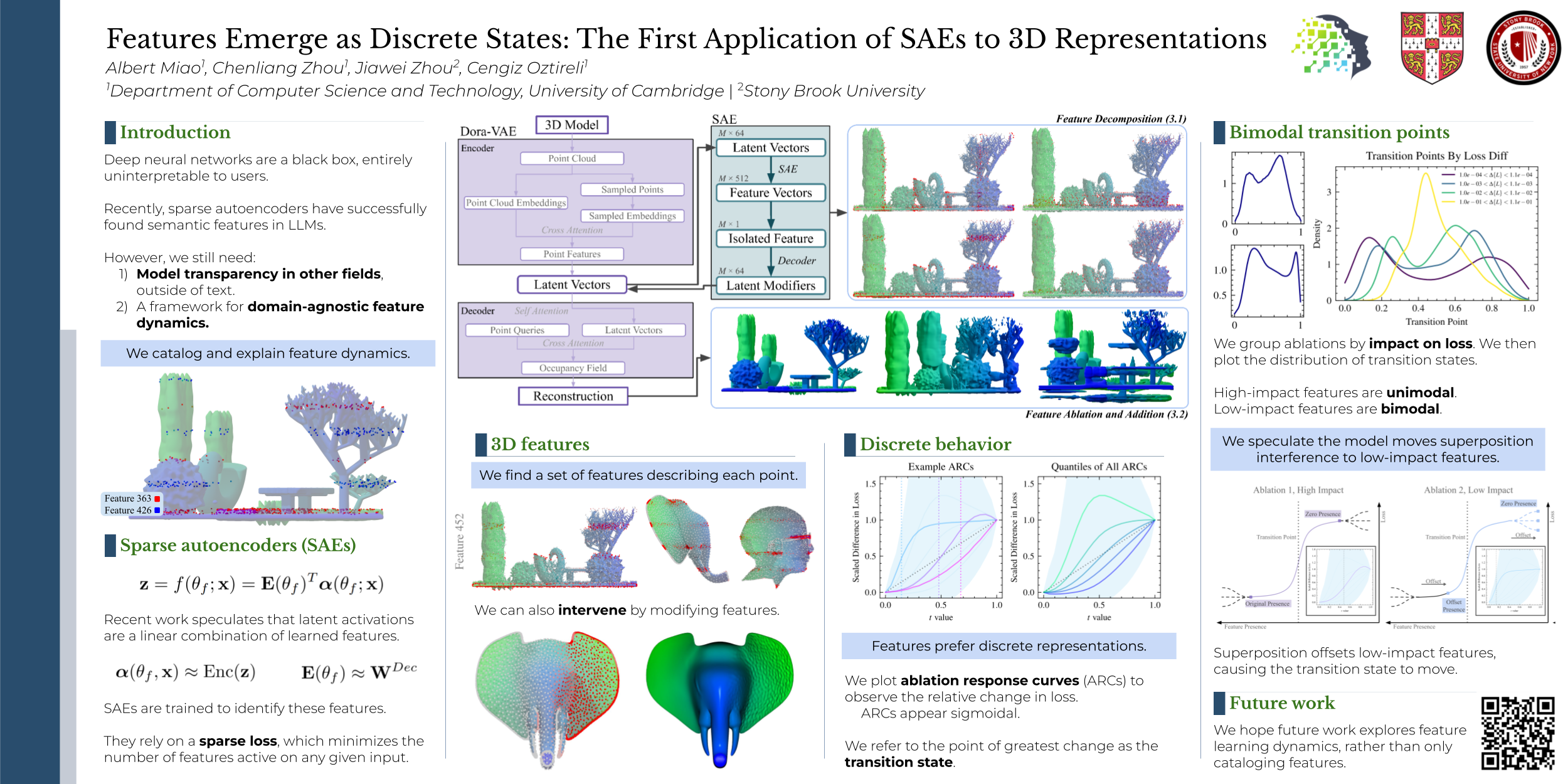
Sparse Autoencoders (SAEs) have found human-interpretable features in LLM activations, clarifying how LLMs transform input to output. However, they have rarely been applied outside of text, limiting explorations of feature dynamics. We present the first application of SAEs to the 3D domain, analyzing the features found in 53k 3D objects encoded by a state-of-the-art 3D reconstruction VAE. We observe that the model encodes discrete rather than continuous features, leading to our key finding: the model's feature activations approximate a discrete state space, driven by phase-like transitions. Through this state space framework, we address three otherwise unintuitive behaviors — the preference for positional encoding features, the sigmoidal relationship between feature ablation and reconstruction loss, and the bimodal distribution of phase transition points. This final observation suggests the model redistributes superposition interference to prioritize the high-importance features. Our work not only catalogs and explains unexpected feature dynamics, but also provides a framework to explain the model's learning dynamics. The code is available at https://feature3d.github.io/Dora-SAE/.