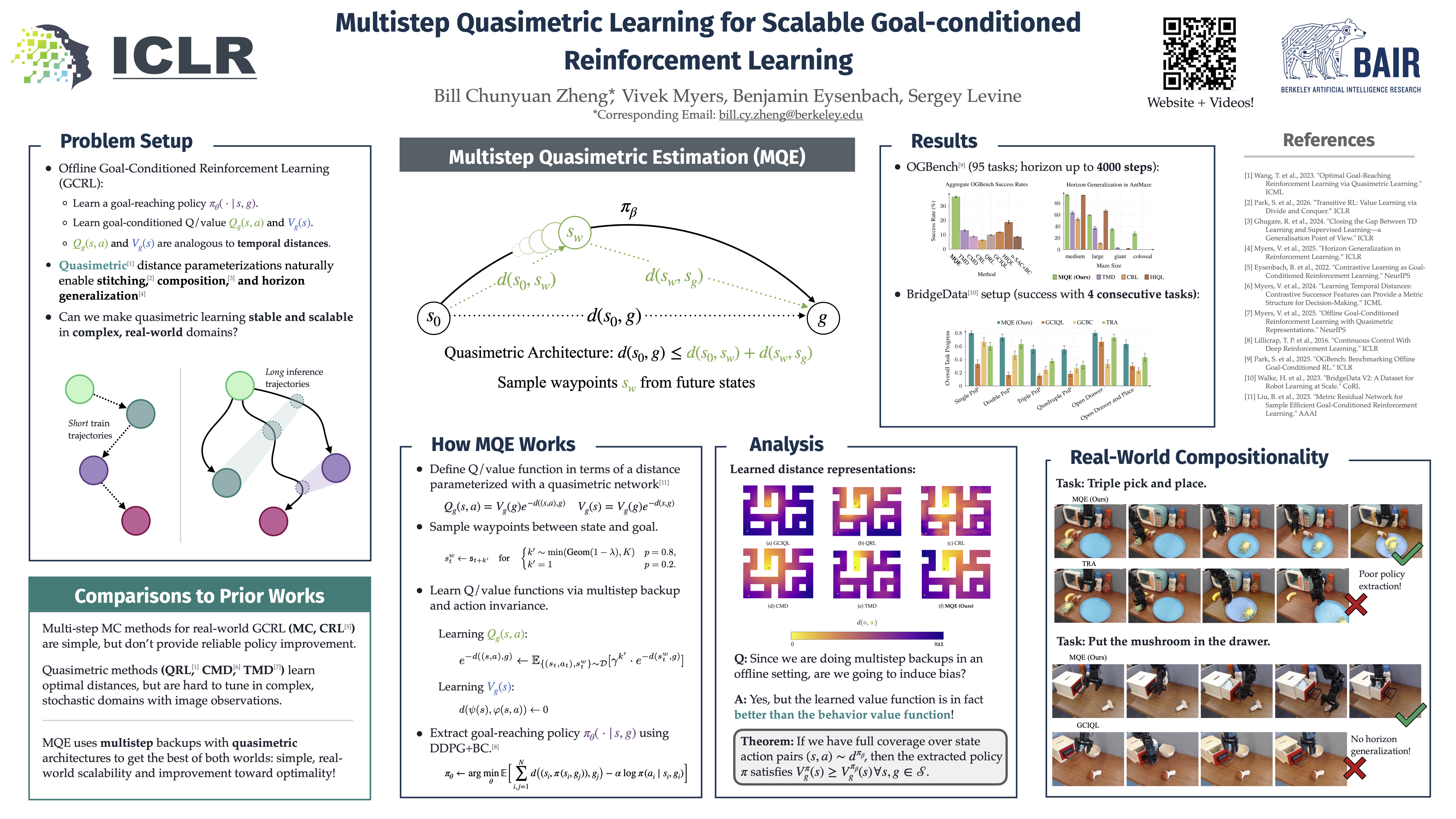
Scaling Goal-conditioned Reinforcement Learning with Multistep Quasimetric Distances
{kind=link}
Abstract
The problem of learning how to reach goals in an environment has been a long- standing challenge in for AI researchers. Effective goal-conditioned reinforcement learning (GCRL) methods promise to enable reaching distant goals without task- specific rewards by stitching together past experiences of different complexity. Mathematically, there is a duality between the notion of optimal goal-reaching value functions (the likelihood of success at reaching a goal) and temporal dis- tances (transit times states). Recent works have exploited this property by learning quasimetric distance representations that stitch long-horizon behaviors using the in- ductive bias of their architecture. These methods have shown promise in simulated benchmarks, reducing value learning to a shortest-path problem. But quasimet- ric, and more generally, goal-conditioned RL methods still struggle in complex environments with stochasticity and high-dimensional (visual) observations. There is a fundamental tension between the local dynamic programming (TD backups, temporal distances) that enables optimal shortest-path reasoning in theory and the statistical global MC updates (multistep returns, suboptimal in theory). We show how these approaches can be integrated into a practical GCRL method that fits a quasimetric distance using a multistep Monte-Carlo return. We show our method outperforms existing GCRL methods on long-horizon simulated tasks with up to 4000 steps, even with visual observations. We also demonstrate that our method can enable stitching in the real-world robotic manipulation domain (Bridge setup). Our approach is the first end-to-end GCRL method that enables multistep stitching in this real-world manipulation domain from an unlabeled offline dataset of visual observations.