Improved Adversarial Diffusion Compression for Real-World Video Super-Resolution
Bin Chen ⋅ Weiqi Li ⋅ Shijie Zhao ⋅ Xuanyu Zhang ⋅ Junlin Li ⋅ Li zhang ⋅ Jian Zhang
{kind=link}
Abstract
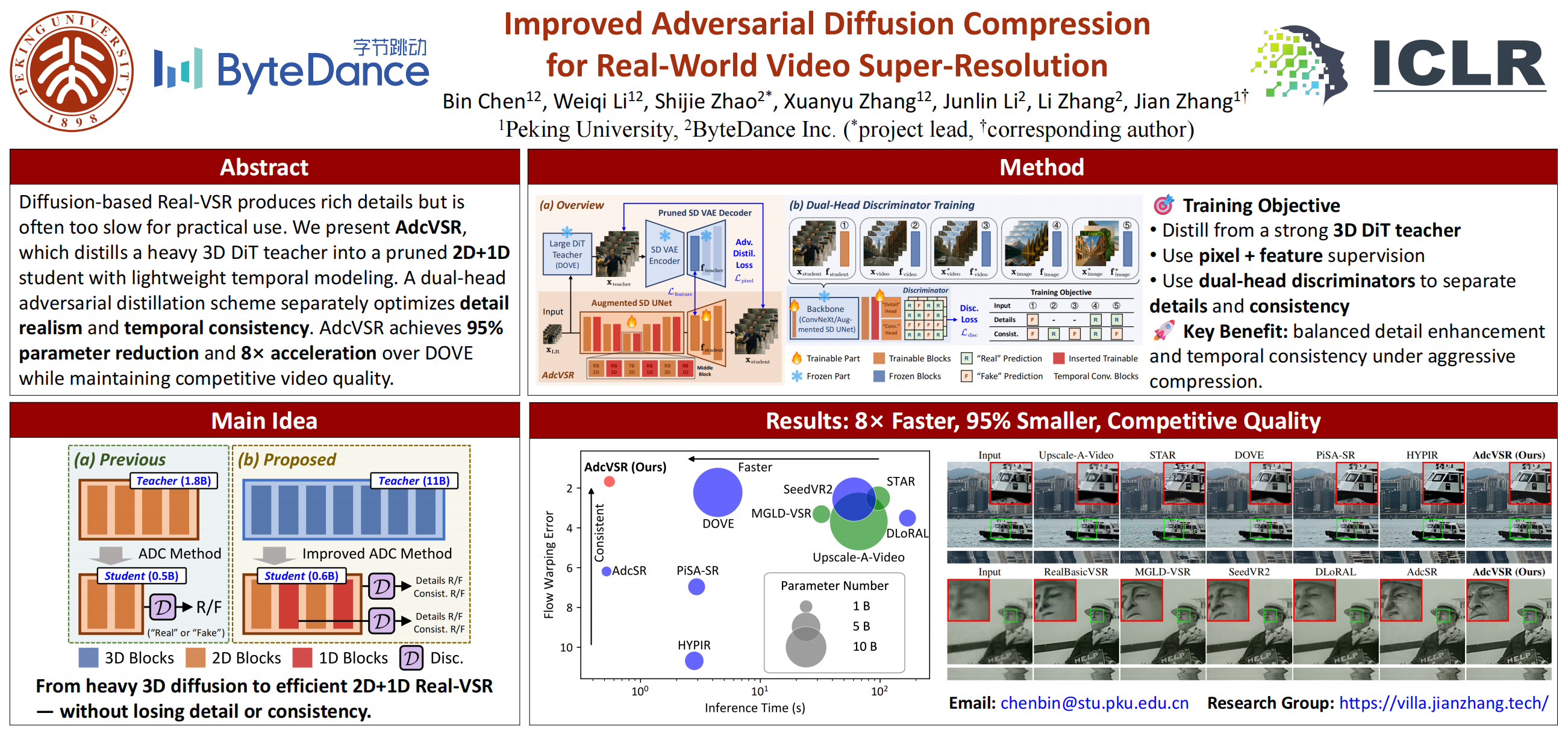
While many diffusion models have achieved impressive results in real-world video super-resolution (Real-VSR) by generating rich and realistic details, their reliance on multi-step sampling leads to slow inference. One-step networks like SeedVR2, DOVE, and DLoRAL alleviate this through condensing generation into one single step, yet they remain heavy, with billions of parameters and multi-second latency. Recent adversarial diffusion compression (ADC) offers a promising path via pruning and distilling these models into a compact AdcSR network, but directly applying it to Real-VSR fails to balance spatial details and temporal consistency due to its lack of temporal awareness and the limitations of standard adversarial learning. To address these challenges, we propose an improved **ADC** method for Real-**VSR**. Our approach distills a large diffusion Transformer (DiT) teacher DOVE equipped with 3D spatio-temporal attentions, into a pruned 2D Stable Diffusion (SD)-based AdcSR backbone, augmented with lightweight 1D temporal convolutions, achieving significantly higher efficiency. In addition, we introduce a dual-head adversarial distillation scheme, in which discriminators in both pixel and feature domains explicitly disentangle the discrimination of details and consistency into two heads, enabling both objectives to be effectively optimized without sacrificing one for the other. Experiments demonstrate that the resulting compressed **AdcVSR** model reduces complexity by **95%** in parameters and achieves an **8$\times$** acceleration over its DiT teacher DOVE, while maintaining competitive video quality and efficiency.
Video
Chat is not available.
Successful Page Load