Scenethesis: A Language and Vision Agentic Framework for 3D Scene Generation
{kind=link}
Abstract
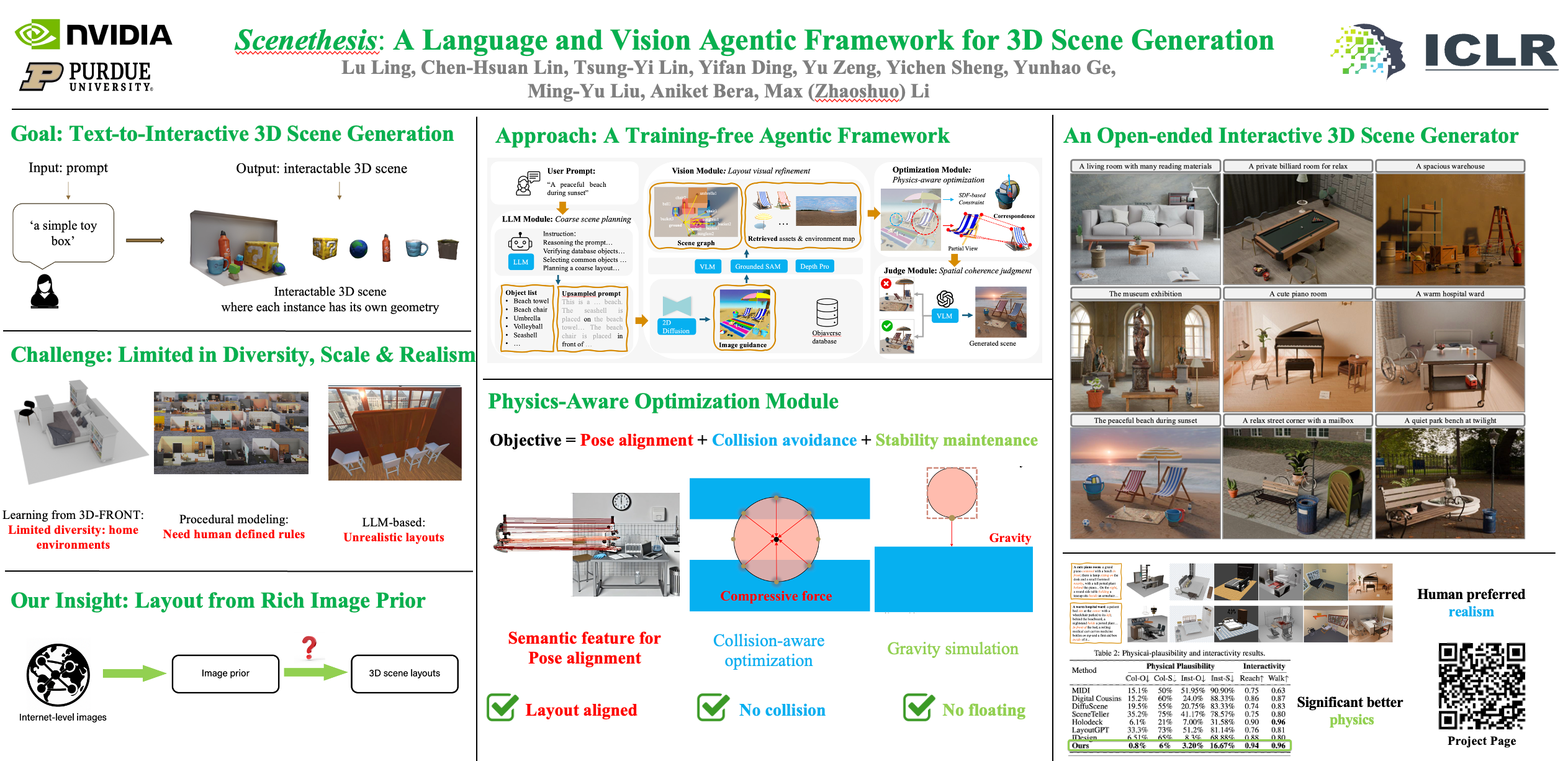
Generating interactive 3D scenes from text requires not only synthesizing assets but arranging them with spatial intelligence—support, affordances, and plausibility. However, training data for interactive scenes is dominated by a few indoor datasets, so learning-based methods overfit to in-distribution layouts and struggle to compose diverse arrangements (e.g., outdoor settings and small-on-large relations). Meanwhile, LLM-based layout planners can propose diverse arrangements, but the lack of visual grounding often yields implausible placements that violate commonsense physics. We propose Scenethesis, a training-free, agentic framework that couples LLM-based scene planning with vision-guided layout refinement. Given a text prompt, Scenethesis first drafts a coarse layout with an LLM; a vision module refines the layout and extracts scene structure to capture inter-object relations. A novel optimization stage enforces pose alignment and physical plausibility, and a final judge verifies spatial coherence and triggers targeted repair when needed. Across indoor and outdoor prompts, Scenethesis produces realistic, relation-rich, and physically plausible 3D interactive scenes, reducing collisions and stability failures compared to SOTA methods, making it practical for virtual content creation, simulation, and embodied AI.