Visual Self-Refine: A Pixel-Guided Paradigm for Accurate Chart Parsing
{kind=link}
Abstract
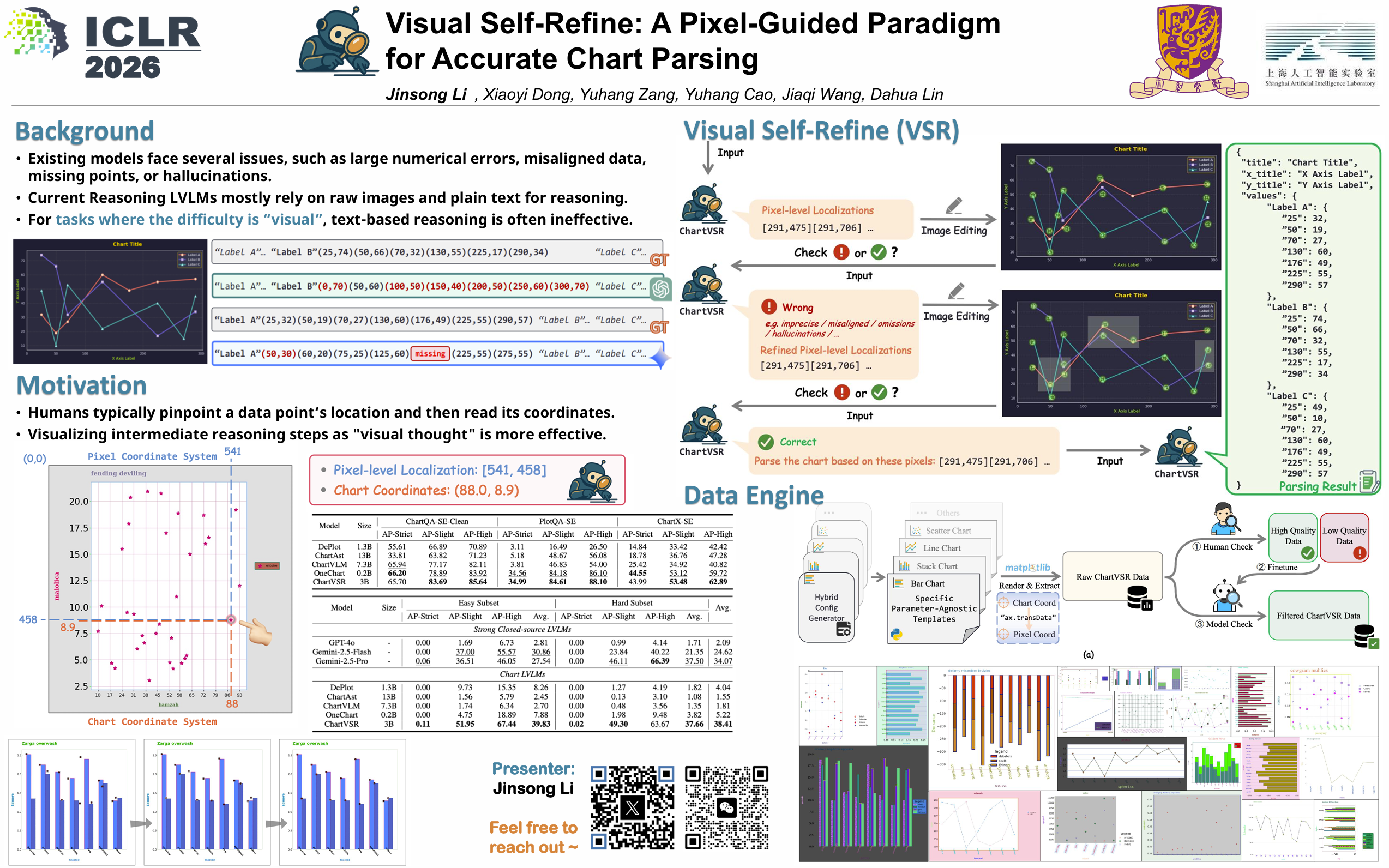
While Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities for reasoning and self-correction at the textual level, these strengths provide minimal benefits for complex tasks centered on visual perception, such as Chart Parsing. Existing models often struggle with visually dense charts, leading to errors like data omission, misalignment, and hallucination. Inspired by the human strategy of using a finger as a ``visual anchor'' to ensure accuracy when reading complex charts, we propose a new paradigm named Visual Self-Refine (VSR). The core idea of VSR is to enable a model to generate pixel-level localization outputs, visualize them, and then feed these visualizations back to itself, allowing it to intuitively inspect and correct its own potential visual perception errors. We instantiate the VSR paradigm in the domain of Chart Parsing by proposing ChartVSR. This model decomposes the parsing process into two stages: a Refine Stage, where it iteratively uses visual feedback to ensure the accuracy of all data points' Pixel-level Localizations, and a Decode Stage, where it uses these verified localizations as precise visual anchors to parse the final structured data. To address the limitations of existing benchmarks, we also construct ChartP-Bench, a new and highly challenging benchmark for chart parsing. Our work also highlights VSR as a general-purpose visual feedback mechanism, offering a promising new direction for enhancing accuracy on a wide range of vision-centric tasks.