ES-dLLM: Efficient Inference for Diffusion Large Language Models by Early-Skipping
Zijian Zhu ⋅ Fei Ren ⋅ Zhanhong Tan ⋅ Kaisheng Ma
{kind=link}
Abstract
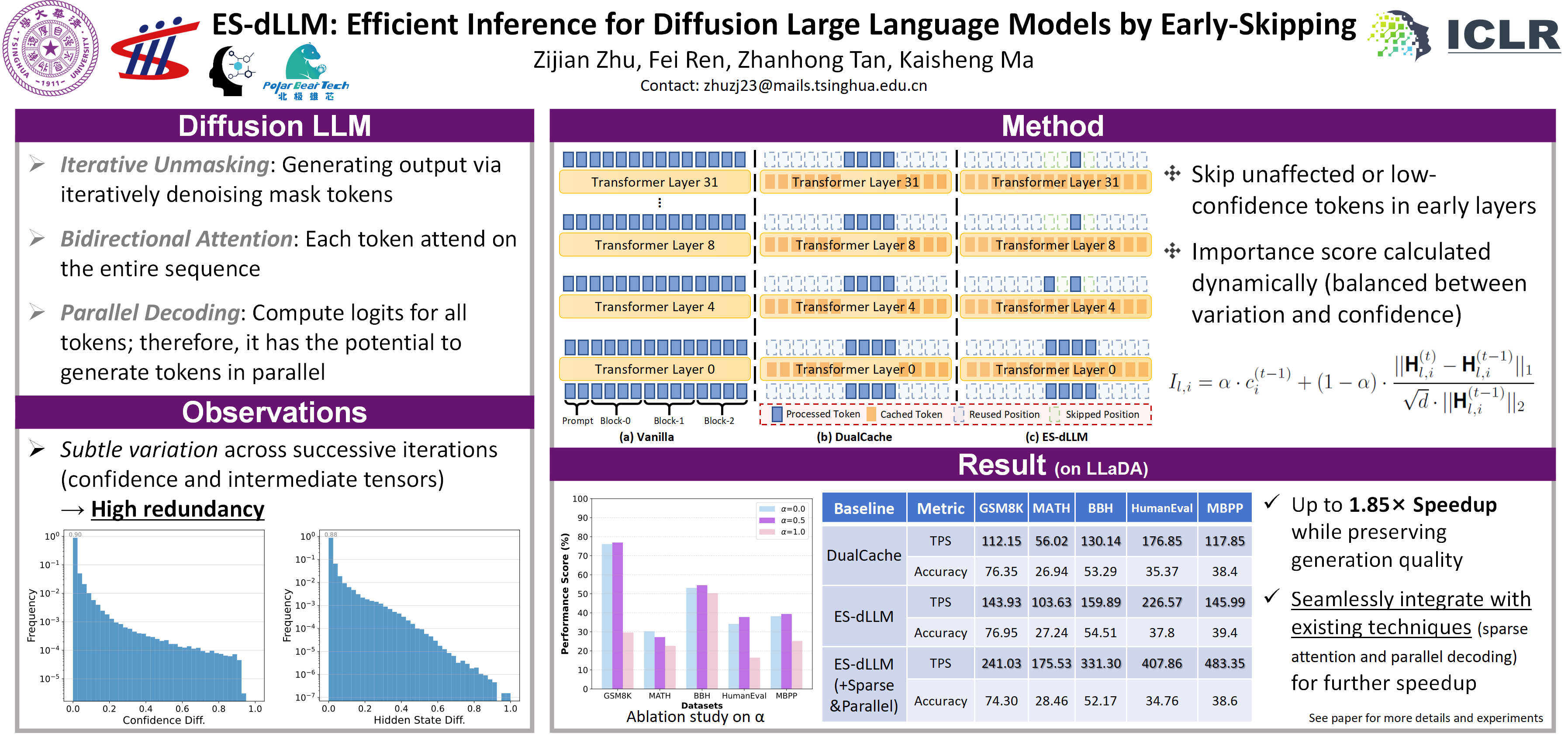
Diffusion large language models (dLLMs) are emerging as a promising alternative to autoregressive models (ARMs) due to their ability to capture bidirectional context and the potential for parallel generation. Despite the advantages, dLLM inference remains computationally expensive as the full input context is processed at every iteration. In this work, we analyze the generation dynamics of dLLMs and find that intermediate representations, including key, value, and hidden states, change only subtly across successive iterations. Leveraging this insight, we propose ES-dLLM, a training-free inference acceleration framework for dLLM that reduces computation by skipping tokens in early layers based on the estimated importance. Token importance is computed with intermediate tensor variation and confidence scores of previous iterations. Experiments on LLaDA-8B and Dream-7B demonstrate that ES-dLLM achieves throughput of up to 226.57 and 308.51 tokens per second (TPS), respectively, on an NVIDIA H200 GPU, delivering 5.6$\times$ to 16.8$\times$ speedup over the vanilla implementation and up to 1.85$\times$ over the state-of-the-art caching method, while preserving generation quality.
Video
Chat is not available.
Successful Page Load