Understanding the Dynamics of Forgetting and Generalization in Continual Learning via the Neural Tangent Kernel
{kind=link}
Abstract
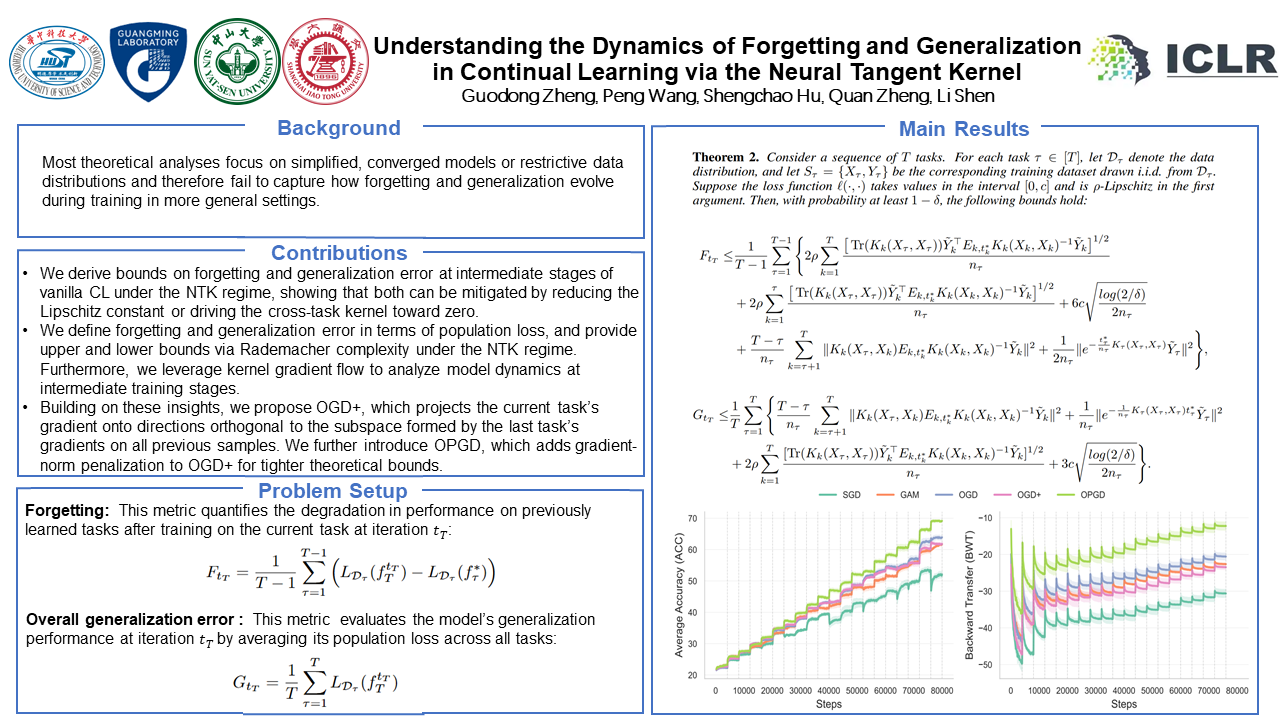
Continual learning (CL) enables models to acquire new tasks sequentially while retaining previously learned knowledge. However, most theoretical analyses focus on simplified, converged models or restrictive data distributions and therefore fail to capture how forgetting and generalization evolve during training in more general settings. Current theory faces two fundamental challenges: (i) analyses confined to the converged regime cannot characterize intermediate training dynamics; and (ii) establishing forgetting bounds requires two-sided bounds on the population risk for each task. To address these challenges, we analyze the training-time dynamics of forgetting and generalization in standard CL within the Neural Tangent Kernel (NTK) regime, showing that decreasing the loss’s Lipschitz constant and minimizing the cross-task kernel jointly reduce forgetting and improve generalization. Specifically, we (i) characterize intermediate training stages via kernel gradient flow and (ii) employ Rademacher complexity to derive both upper and lower bounds on population risk. Building on these insights, we propose \emph{OGD+}, which projects the current task’s gradient onto the orthogonal complement of the subspace spanned by gradients of the most recent task evaluated on all prior samples. We further introduce \emph{Orthogonal Penalized Gradient Descent} (OPGD), which augments OGD+ with gradient-norm penalization to jointly reduce forgetting and enhance generalization. Experiments on multiple benchmarks corroborate our theoretical predictions and demonstrate the effectiveness of OPGD, providing a principled pathway from theory to algorithm design in CL.