$\textbf{Re}^{2}$: Unlocking LLM Reasoning via Reinforcement Learning with Re-solving
Pinzheng Wang ⋅ Shuli Xu ⋅ Juntao Li ⋅ Yu Luo ⋅ Dong Li ⋅ Jianye Hao ⋅ Min Zhang
{kind=link}
Abstract
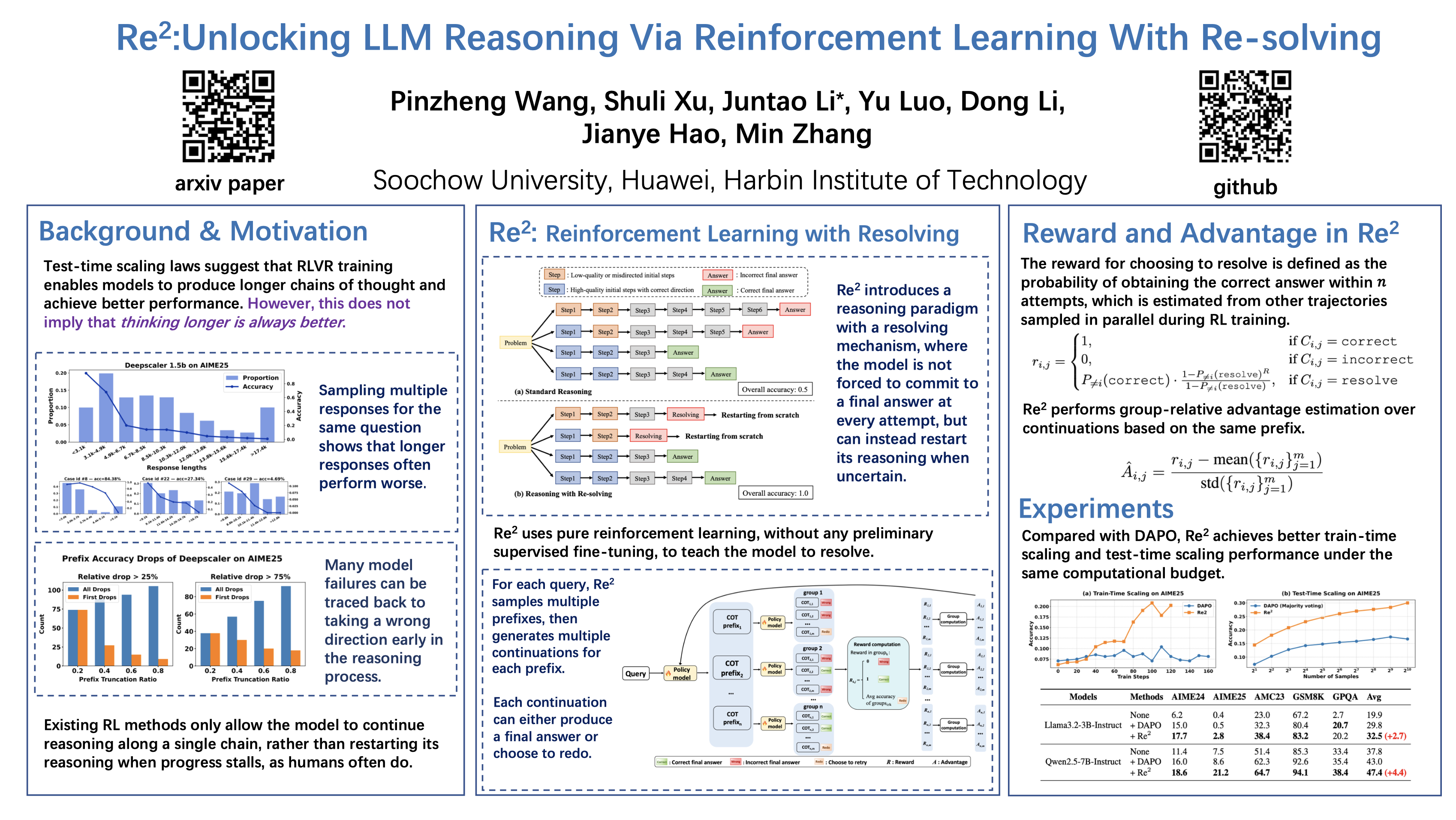
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning performance of large language models (LLMs) by increasing test-time compute. However, even after extensive RLVR training, such models still tend to generate unnecessary and low-quality steps in their chain-of-thought (CoT), leading to inefficient overthinking and lower answer quality. We show that when the initial direction or quality of the CoT is suboptimal, the model often fails to reach the correct answer, even after generating several times more tokens than when the initial CoT is well-initialized. To this end, we introduce $\textit{\textbf{Re}inforcement Learning with \textbf{Re}-solving}$ (Re$^2$), in which LLMs learn to flexibly abandon unproductive reasoning paths and restart the solution process when necessary, rather than always committing to a final answer. Re$^2$ applies pure reinforcement learning without any preliminary supervised fine-tuning, successfully amplifying the rare redo behavior in vanilla models from only 0.5\% to over 30\%. This leads to substantial performance gains over standard RLVR under the same training compute budget, and also demonstrates notable improvements in test-time performance as the number of samples increases.
Video
Chat is not available.
Successful Page Load