LoRA-Mixer: Coordinate Modular LoRA Experts Through Serial Attention Routing
{kind=link}
Abstract
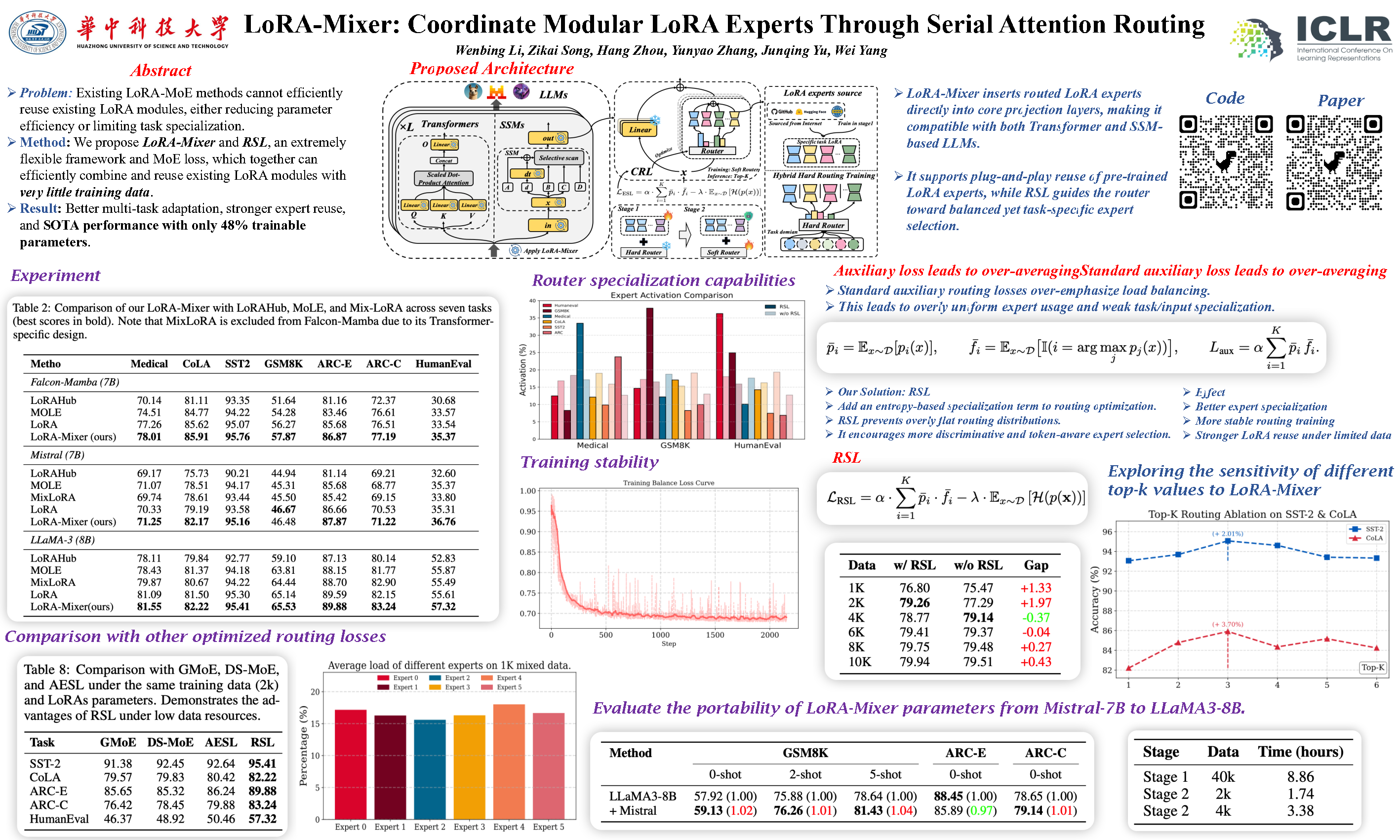
Recent attempts to combine low-rank adaptation (LoRA) with mixture-of-experts (MoE) for multi-task adaptation of Large Language Models (LLMs) often replace whole attention/FFN layers with switch experts or append parallel expert branches, undermining parameter efficiency and limiting task specialization. We introduce LoRA-Mixer, a modular MoE framework that routes task-specific LoRA experts into the core projection matrices of the attention module (input/output linear layers), rather than primarily targeting FFN blocks. The design delivers fine-grained token-level specialization by fully exploiting the attention mechanism, while remaining drop-in compatible with Transformers and state-space models (SSMs) as the linear projection layers are ubiquitous. To train robust routers from limited data while promoting stable, selective decisions and high expert reuse, LoRA-Mixer employs an adaptive Routing Specialization Loss (RSL) that jointly enforces global load balance and input-aware specialization via an entropy-shaping objective. The framework supports two regimes: (i) joint optimization of adapters and router with a differentiable hard–soft top-k routing scheme, and (ii) plug-and-play routing over frozen, pre-trained LoRA modules sourced from public repositories. Across 15 benchmarks—including MedQA, GSM8K, HumanEval, and GLUE—RSL-optimized LoRA-Mixer outperforms state-of-the-art routing and LoRA-MoE baselines while using 48% of their trainable parameters, with gains of +3.79%, +2.90%, and +3.95% on GSM8K, CoLA, and ARC-C, respectively. Cross-model transfer and adapter reuse experiments further demonstrate the approach’s versatility and data efficiency.