PromptHub: Enhancing Multi-Prompt Visual In-Context Learning with Locality-Aware Fusion, Concentration and Alignment
{kind=link}
Abstract
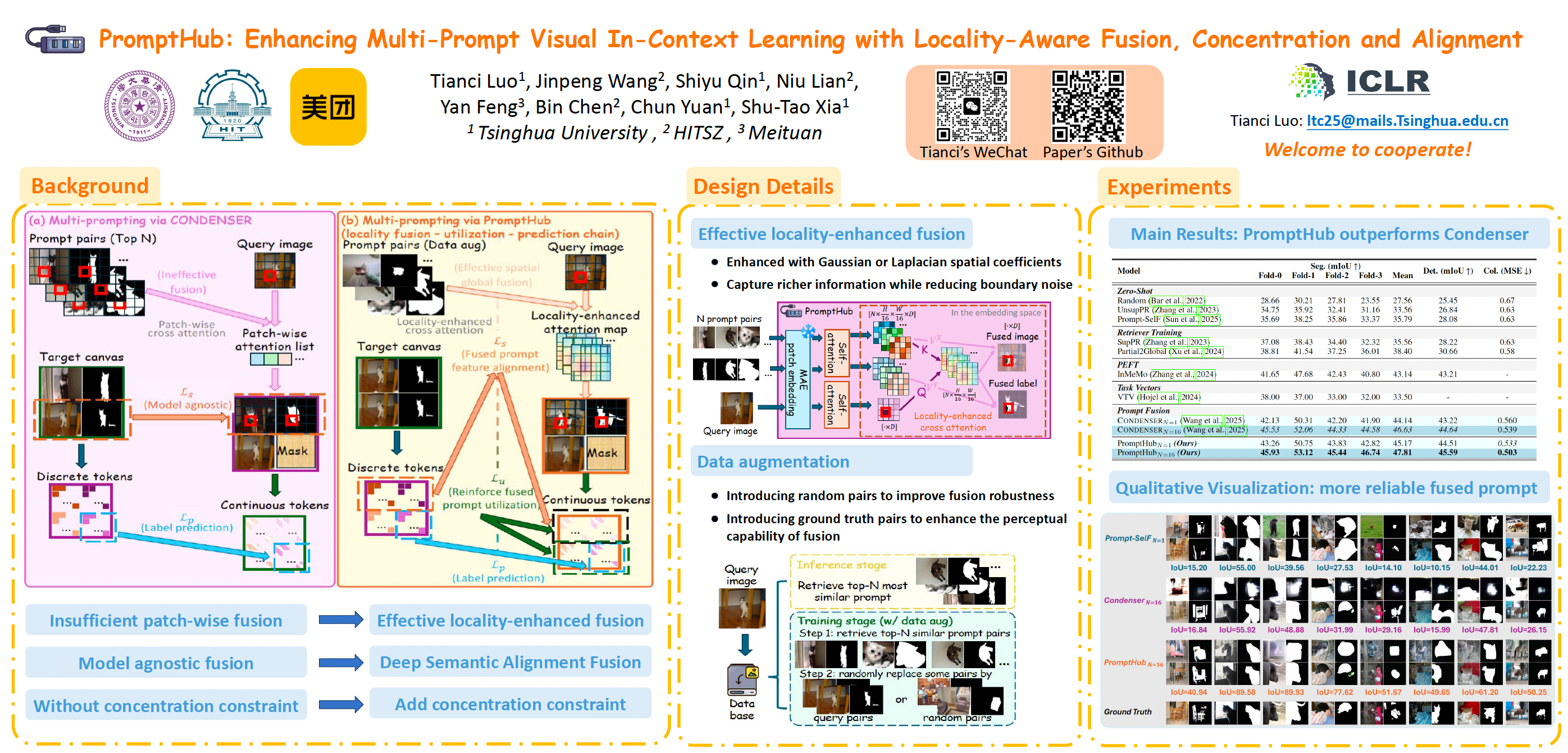
Visual In-Context Learning (VICL) aims to complete vision tasks by imitating pixel demonstrations. Recent work Condenser pioneered prompt fusion that combines the advantages of various demonstrations, which shows a promising way to extend VICL. Unfortunately, the patch-wise fusion framework and model-agnostic supervision hinder the exploitation of informative cues, thereby limiting performance gains. To overcome this deficiency, we introduce PromptHub, a framework that holistically strengthens multi-prompting through locality-aware fusion, concentration and alignment. PromptHub exploits spatial priors to capture richer contextual information, employs complementary concentration, alignment, and prediction objectives to mutually guide training, and incorporates data augmentation to further reinforce supervision. Extensive experiments on three fundamental vision tasks demonstrate the superiority of PromptHub. Moreover, we validate its universality, transferability, and robustness across out-of-distribution settings, and various retrieval scenarios. This work establishes a reliable locality-aware paradigm for prompt fusion, moving beyond prior patch-wise approaches. Code is available at https://github.com/luotc-why/ICLR26-PromptHub.