TD-MoE: Tensor Decomposition for MoE Models
{kind=link}
Abstract
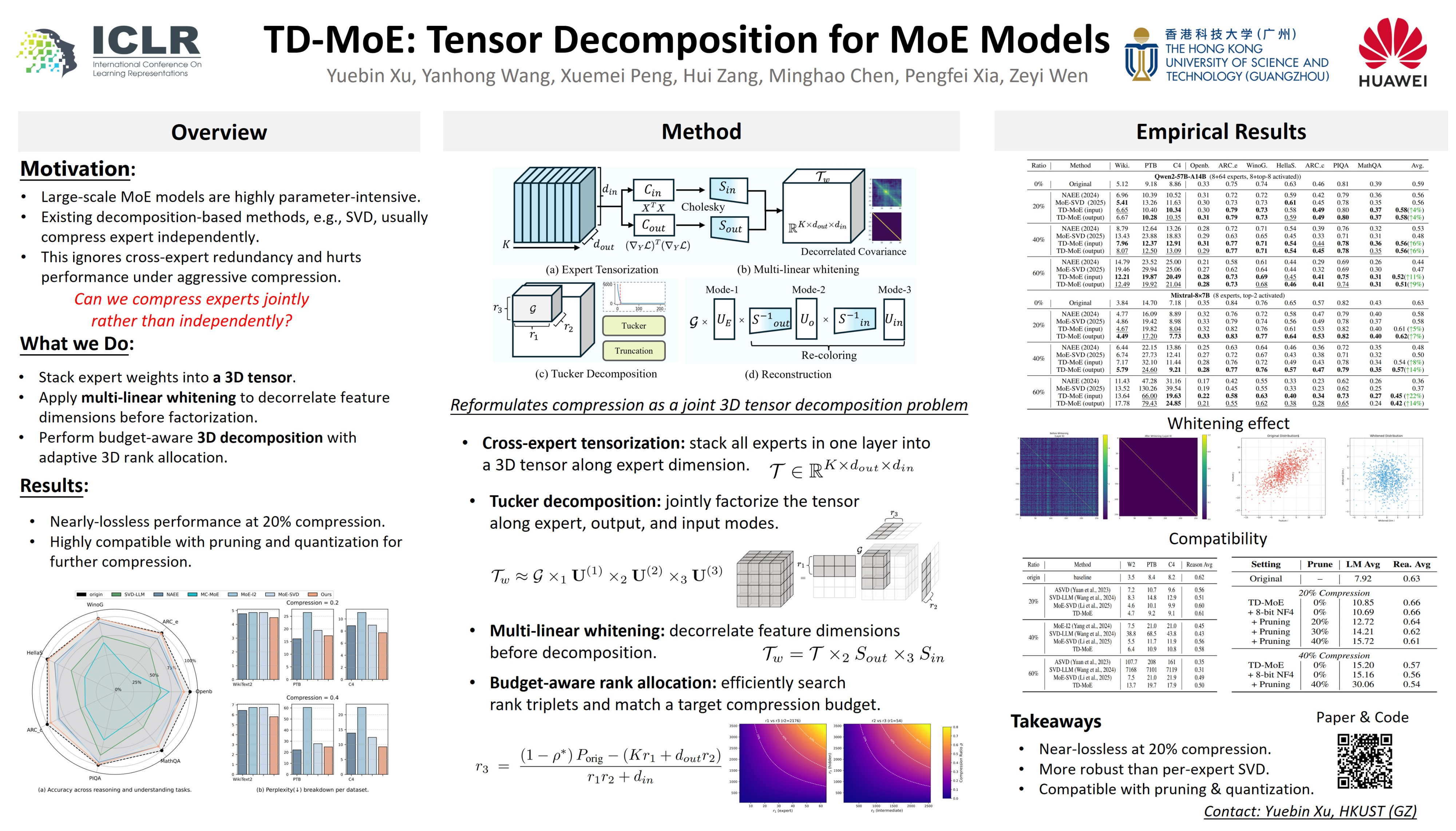
Mixture-of-Experts (MoE) architectures have demonstrated remarkable capabilities and scalability for large language models, but incur a substantial memory footprint due to redundant expert parameters. Existing compression approaches, particularly those based on low-rank decomposition, typically operate at the granularity of individual experts. However, such per-expert methods neglect structural redundancies shared across experts, limiting their compression efficiency and effectiveness. In this work, we introduce TD-MoE (Tensor Decomposition for MoE Compression), a data-aware method that jointly factorizes expert weights by capturing global dependencies. Our contributions are threefold: (i) Cross-expert tensorization with joint three-dimensional decomposition, which unifies all experts within a layer into a single tensor and captures shared structure beyond per-expert scope; (ii) A multi-linear whitening strategy, which decorrelates input and output features, yielding a more balanced and data-adaptive decomposition; (iii) A three-dimensional rank allocation mechanism, which dynamically assigns 3D decomposition ranks across dimensions to best meet a target compression ratio while minimizing the reconstruction error. Extensive experiments on Qwen2-57B-A14B and Mixtral-8×7B across seven commonsense reasoning benchmarks demonstrate that TD-MoE achieves almost lossless performance under 20\% parameter reduction, and delivers more than 11\% and 14\% gains over state-of-the-art decomposition-based baselines at 40\% and 60\% compression. Further ablation studies validate the effectiveness of each component, highlighting the importance of joint factorization, whitening, and rank allocation. Codes are available at https://github.com/ust-xu/TD-MoE.