Rethinking LLM Reasoning: From Explicit Trajectories to Latent Representations
{kind=link}
Abstract
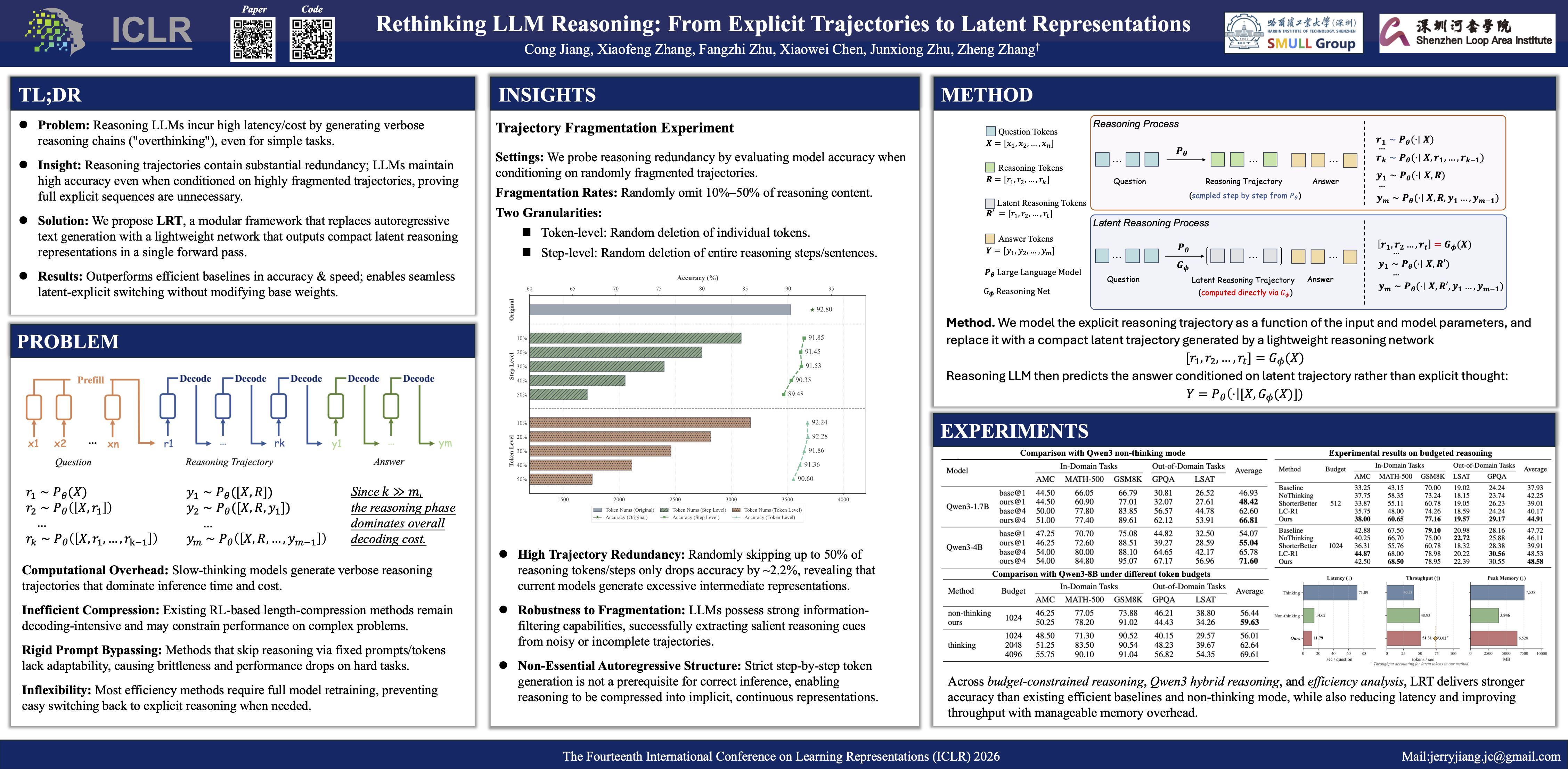
Large Language Models (LLMs) have achieved impressive performance on complex tasks by generating human-like, step-by-step rationales, referred to as \textit{reasoning trajectory}, before arriving at final answers. However, the length of these reasoning trajectories often far exceeds that of the final answers, which incurs substantial inference costs even for relatively simple tasks. Advanced methods typically attempt to compress reasoning trajectory length through post-training, but they remain decoding-intensive and fail to inherently mitigate the efficiency challenge. In this work, we challenge the necessity of generating full reasoning trajectories and empirically demonstrate that LLMs can generate accurate answers using only fragmental reasoning paths, without relying on complete token-by-token sequences. To this end, we propose a novel \textbf{Latent Reasoning Tuning (LRT)} framework, which empowers LLMs to perform reasoning using implicit, compact, learnable representations instead of explicit textual trajectories. Technically, LRT replaces the costly autoregressive generation of reasoning steps with a single forward pass through a lightweight reasoning network, which generates latent vectors that encapsulate the necessary reasoning logic and condition the LLM to produce the final answer. Experiments on mathematical and out-of-domain benchmarks demonstrate that our LRT consistently outperforms relevant efficient reasoning methods. Moreover, by transforming explicit reasoning into latent reasoning, our approach surpasses the state-of-the-art Qwen3 hybrid reasoning framework. Code is available at \texttt{https://github.com/MobiusDai/LRT} .