Difference-Aware Retrieval Policies for Imitation Learning
{kind=link}
Abstract
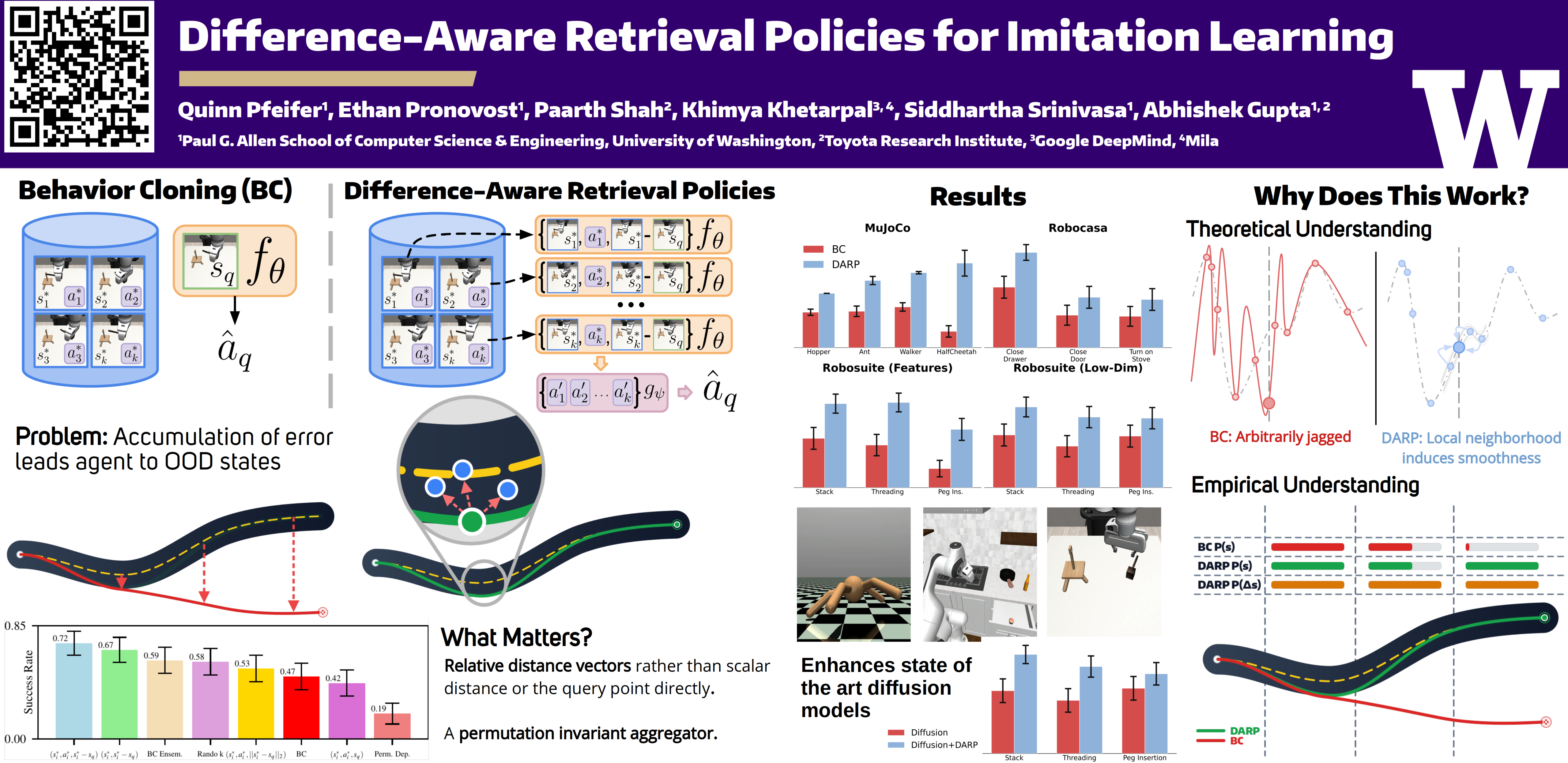
Parametric imitation learning via behavior cloning can suffer from poor generalization to out-of-distribution states due to compounding errors during deployment. We show that reusing the training data during inference via a semi-parametric retrieval-based imitation learning approach can alleviate this challenge. We present Difference-Aware Retrieval Policies for Imitation Learning (DARP), a semi-parametric retrieval-based imitation learning approach that addresses this limitation by reparameterizing the imitation learning problem in terms of local neighborhood structure rather than direct state-to-action mappings. Instead of learning a global policy, DARP trains a model to predict actions based on k-nearest neighbors from expert demonstrations, their corresponding actions, and the relative distance vectors between neighbor states and query states. DARP requires no additional assumptions beyond those made for standard behavior cloning -- it does not require additional data collection, online expert feedback, or task-specific knowledge. We demonstrate consistent performance improvements of 15-46% over standard behavior cloning across diverse domains, including continuous control and robotic manipulation, and across different representations, including high-dimensional visual features.