Cross-ControlNet: Training-Free Fusion of Multiple Conditions for Text-to-Image Generation
{kind=link}
Abstract
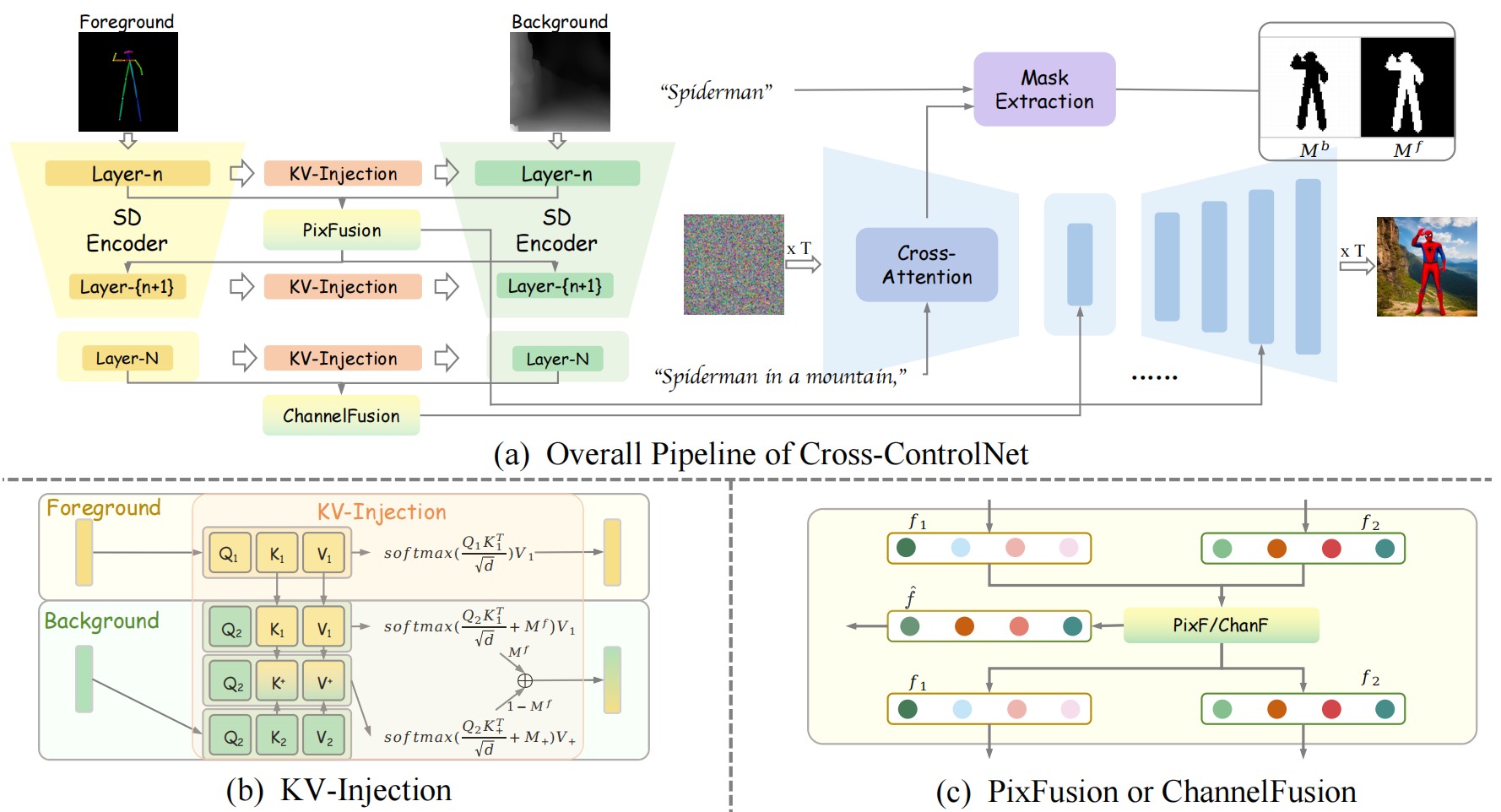
Text-to-image diffusion models achieve impressive performance, but reconciling multiple spatial conditions usually requires costly retraining or labor intensive weight tuning. We introduce Cross-ControlNet, a training-free framework for text-to-image generation with multiple conditions. It exploits two observations: intermediate features from different ControlNet branches are spatially aligned, and their condition strength can be measured by spatial and channel level variance. Cross-ControlNet contains three modules: PixFusion, which fuses features pixelwise under the guidance of standard deviation maps smoothed by a Gaussian to suppress early-stage noise; ChannelFusion, which applies per channel hybrid fusion via a consistency ratio gate, reducing threshold degradation in high dimensions; and KV-Injection, which injects foreground- and background-specific key/value pairs under text-derived attention masks to disentangle conflicting cues and enforce each condition faithfully. Extensive experiments demonstrate that Cross-ControlNet consistently improves controllable generation under both conflicting and complementary conditions, and further generalizes to the DiT-based FLUX model without additional training.