MVR: Multi-view Video Reward Shaping for Reinforcement Learning
{kind=link}
Abstract
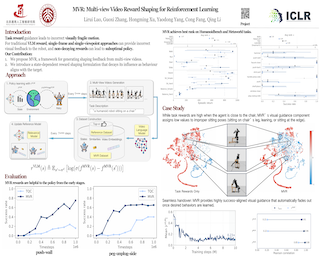
Reward design is of great importance for solving complex tasks with reinforcement learning. Recent studies have explored using image-text similarity produced by vision-language models (VLMs) to augment rewards of a task with visual feedback. A common practice linearly adds VLM scores to task or success rewards without explicit shaping, potentially altering the optimal policy. Moreover, such approaches, often relying on single static images, struggle with tasks whose desired behavior involves complex, dynamic motions spanning multiple visually different states. Furthermore, single viewpoints can occlude critical aspects of an agent's behavior. To address these issues, this paper presents Multi-View Video Reward Shaping (MVR), a framework that models the relevance of states regarding the target task using videos captured from multiple viewpoints. MVR leverages video-text similarity from a frozen pre-trained VLM to learn a state relevance function that mitigates the bias towards specific static poses inherent in image-based methods. Additionally, we introduce a state-dependent reward shaping formulation that integrates task-specific rewards and VLM-based guidance, automatically reducing the influence of VLM guidance once the desired motion pattern is achieved. We confirm the efficacy of the proposed framework with extensive experiments on challenging humanoid locomotion tasks from HumanoidBench and manipulation tasks from MetaWorld, verifying the design choices through ablation studies.