Reasoning Language Model Inference Serving Unveiled: An Empirical Study
{kind=link}
Abstract
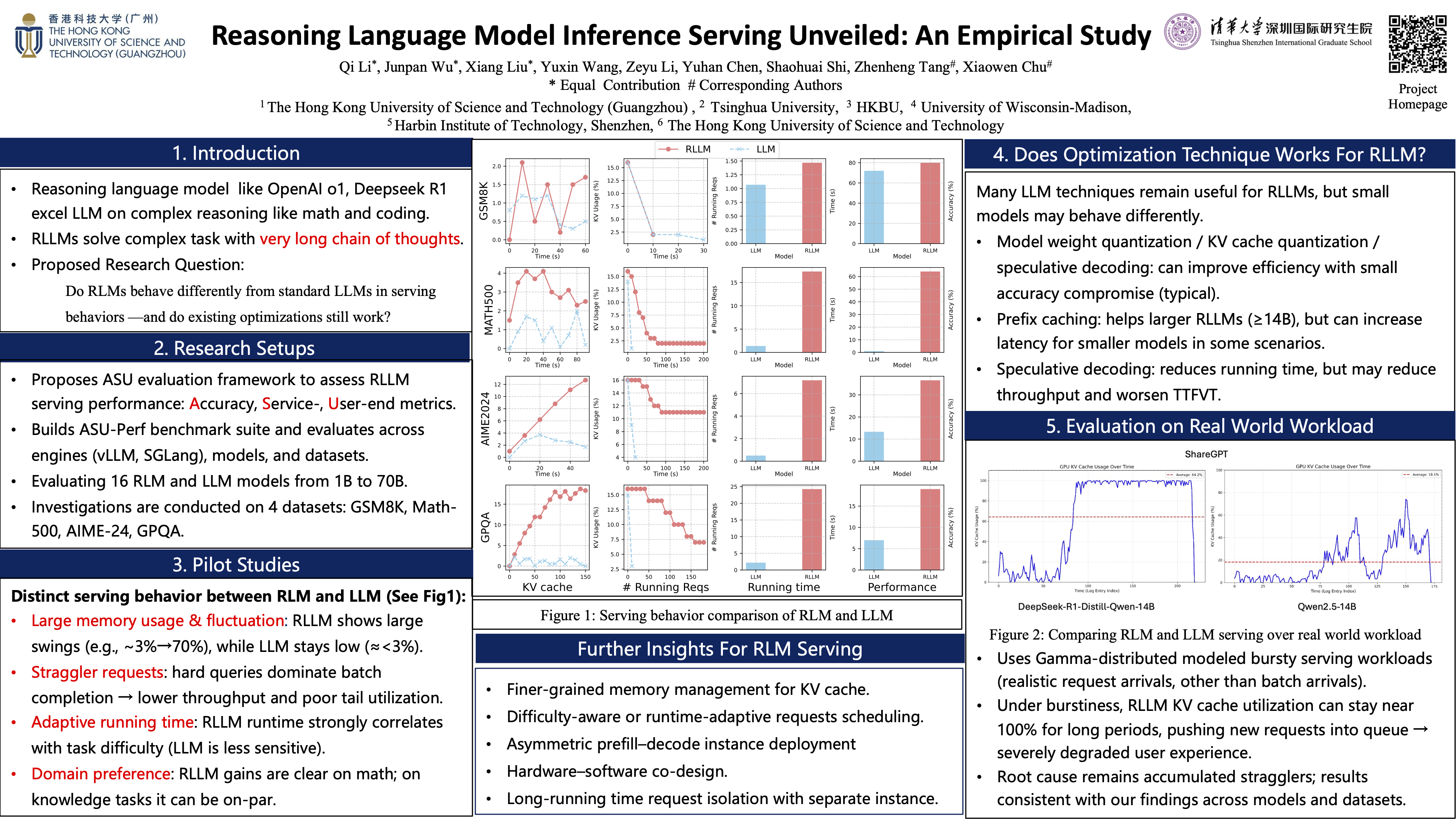
The reasoning large language model (RLLM) has been proven competitive in solving complex reasoning tasks such as mathematics, coding, compared to LLM. However, the serving performance and behavior of RLLM remains \textit{unexplored}, which may undermine the deployment and utilization of RLLM in real-world scenario. To close this gap, in this paper, we conduct a comprehensive study of RLLM service. We first perform a pilot study on comparing the serving performance between RLLM and traditional LLM and reveal that there are several distinct differences regarding serving behavior: (1) \textit{significant memory usage and fluctuations}; (2) \textit{straggler requests}; (3) \textit{adaptive running time}; (4) \textit{domain preference}. Then we further investigate whether existing inference optimization techniques are valid for RLLM. Our main takeaways are that model weight quantization, KV cache quantization, and speculative decoding can improve service system efficiency with small compromise to RLLM accuracy, while prefix caching may degrade inference serving performance for small RLLM in some scenarios. Lastly, we conduct evaluation under real world workload modeled by the Gamma distribution to verify our findings. Empirical results for real-world workload evaluation across different datasets are \textit{aligned} with our main findings regarding RLLM serving. We hope our work can provide the research community and industry with insights to advance RLLM inference serving.