Hyden: A Hybrid Dual-Path Encoder for Monocular Geometry of High-resolution Images
{kind=link}
Abstract
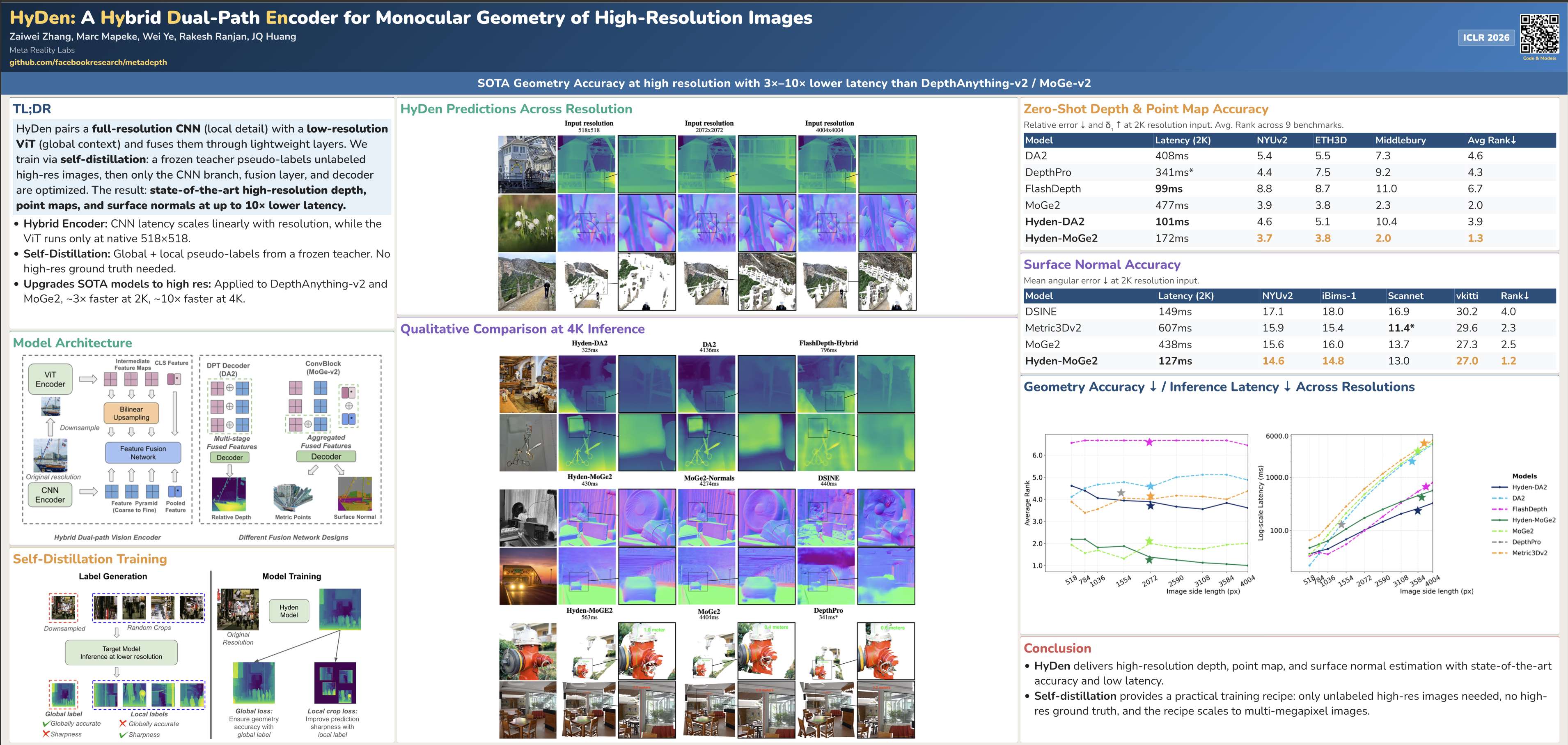
We present a hybrid dual-path vision encoder (Hyden) for high-resolution monocular depth, point map and surface normal estimation, surpassing state-of-the-art accuracy with a fraction of the inference cost. The architecture pairs a low-resolution Vision Transformer branch for global context with a full-resolution CNN branch for fine details, fusing features via a lightweight MLP before decoding. By exploiting the linear scaling of CNNs and constraining transformer computation to a fixed resolution, the model delivers fast inference even on multi-megapixel inputs. To overcome the scarcity of high-quality high-resolution supervision, we introduce a self-distillation framework that generates pseudo-labels from existing models at both lower resolution full images and high-resolution crops—global labels preserve geometric accuracy, while local labels capture sharper details. To demonstrate the flexibility of our approach, we integrate Hyden and our self-distillation method into DepthAnything-v2 for depth estimation and MoGe2 for surface normal and metric point map prediction, achieving state-of-the-art results on high-resolution benchmarks with the lowest inference latency among competing methods.