The Adversarial Conditioning Paradox: Why Attacked Inputs Are More Stable, Not Less
{kind=link}
Abstract
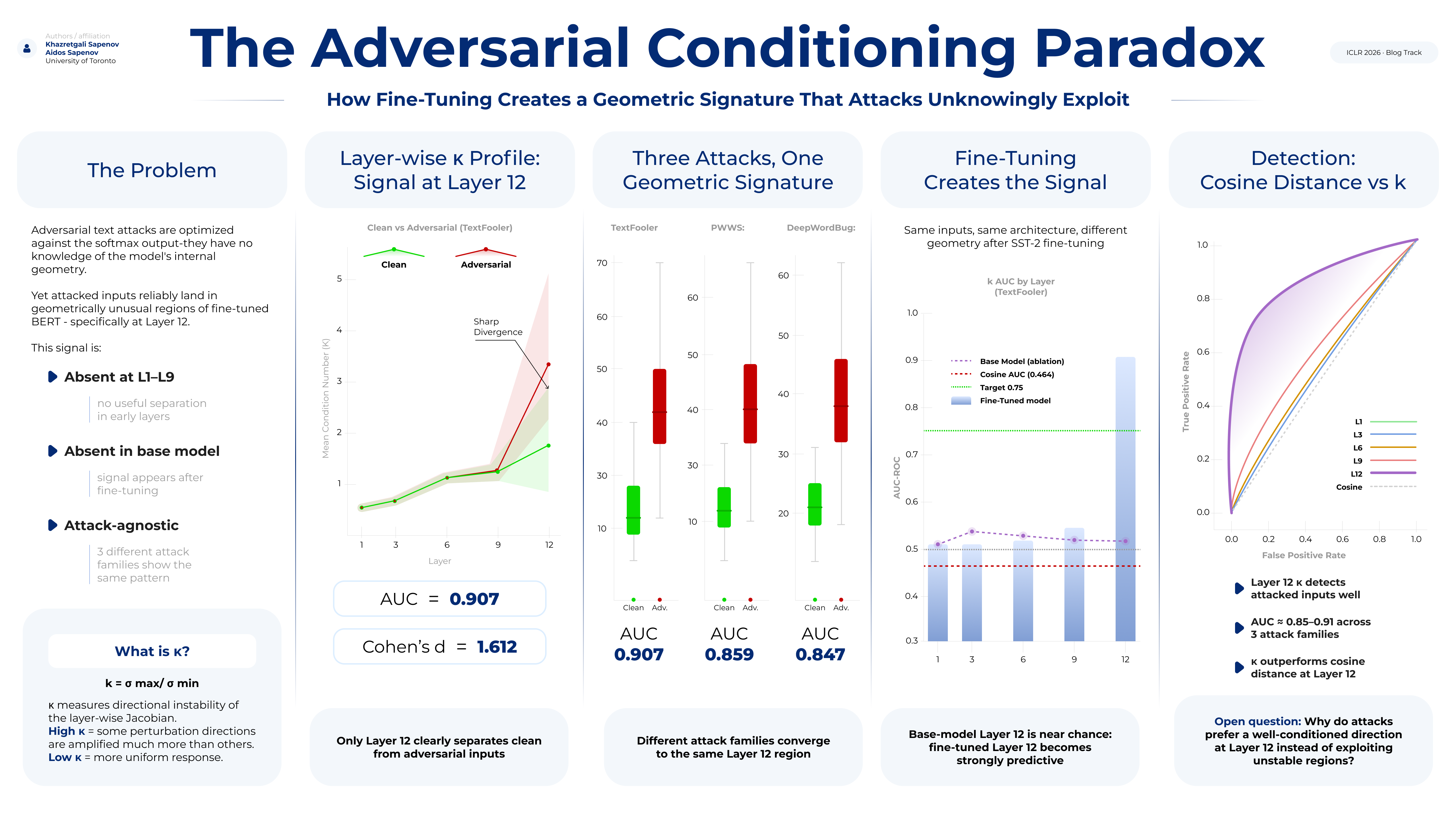
Adversarial attacks on NLP systems are designed to find inputs that fool models while minimizing perceptible changes, making them difficult to detect using similarity-based methods. We investigate whether Jacobian conditioning analysis can provide an orthogonal detection signal. Surprisingly, we find that adversarial inputs exhibit systematically lower condition numbers at early transformer layers—the opposite of our initial hypothesis that attacks exploit unstable, ill-conditioned regions. This “adversarial conditioning paradox” replicates across multiple attack types: TextFooler (AUC = 0.72, p = 0.001), DeepWordBug (AUC = 0.75, p = 0.001), and directionally for PWWS (AUC = 0.59, p = 0.29). The effect holds for both word-level and character-level perturbations, while embedding cosine distance fails completely (AUC ≈ 0.25). We propose that adversarial attacks succeed by finding wellconditioned directions that cross decision boundaries—smooth paths to misclassification rather than chaotic exploitation of instability. Our findings open new directions for adversarial detection using internal geometric properties invisible to embedding-based methods.