ICLR 2022 Reviewer Guide
Thank you for agreeing to serve as an ICLR 2022 reviewer. Your contribution as a reviewer is paramount to creating an exciting and high-quality program. We ask that:
-
Your reviews are timely and substantive.
-
You follow the reviewing guidelines below.
-
You adhere to our Code of Ethics in your role as a reviewer.
-
You must also adhere to our Code of Conduct.
This guide is intended to help you understand the ICLR 2022 decision process and your role within it. It contains:
-
A flowchart outlining the global review process
-
An outline of the main reviewer tasks
-
Step-by-step reviewing instructions (especially relevant for reviewers that are new to ICLR)
-
An FAQ
-
Review examples
We’re counting on you
As a reviewer you are on the front line of the program creation process for ICLR 2022. Your SACs, ACs and the PCs will rely greatly on your expertise and your diligent and thorough reviews to make decisions on each paper. Therefore, your role as a reviewer is critical to ensuring a strong program for ICLR 2022.
High-quality reviews are also very valuable for helping authors improve their work, whether it is eventually accepted by ICLR 2022, or not. Therefore it is important to treat each valid ICLR 2022 submission with equal care.
As a token of our appreciation for your essential work, all reviewers will be acknowledged on the ICLR website. Top reviewers will receive special acknowledgement and free registration to ICLR 2022.
The global review process (simplified)
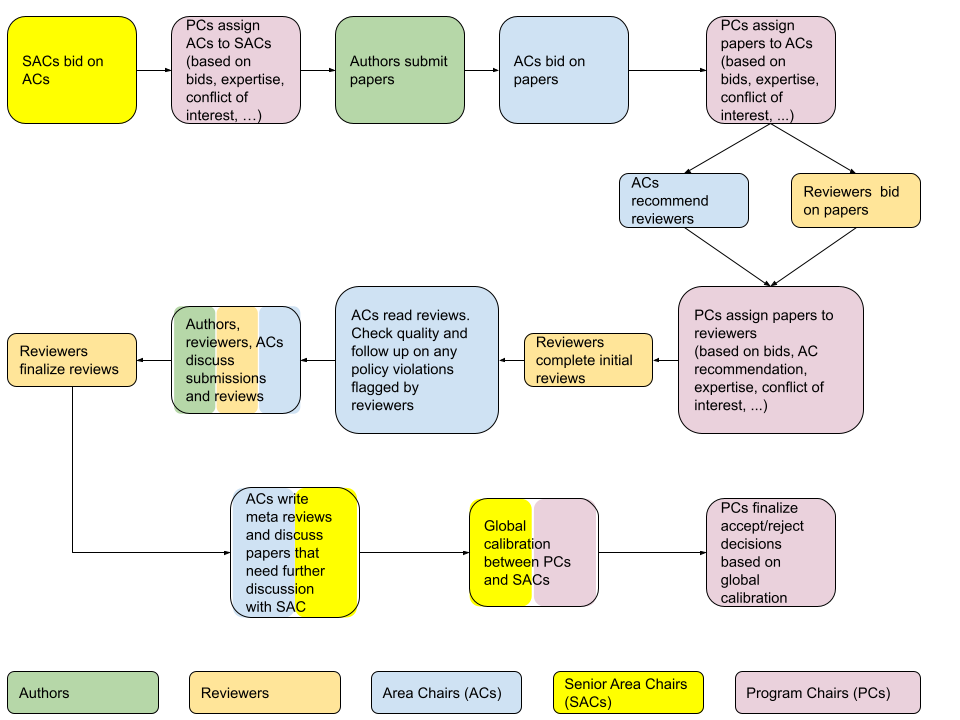
Main reviewer tasks
The main reviewer tasks and dates are as follows:
-
Create your OpenReview profile and link your DBLP profile (by September 15th 2021)
-
Bid on papers (7 October 2021 - 12 October 2021)
-
Write a constructive, thorough and timely review (14 October 2021- 1 November 2021)
-
Discuss with authors, other reviewers, and ACs to clarify and improve the paper (9 November 2021 - 29 November 2021)
-
Provide a final recommendation to the area chair assigned to the paper (by 29 November 2021)
-
Flag any potential CoE violations and/or concerns (throughout the review and discussion phase)
Reviewing a submission: step-by-step
Summarized in one line, a review aims to determine whether a submission will bring sufficient value to the community and contribute new knowledge. The process can be broken down into the following main reviewer tasks:
-
Read the paper: It’s important to carefully read through the entire paper, and to look up any related work and citations that will help you comprehensively evaluate it. Be sure to give yourself sufficient time for this step.
-
While reading, consider the following:
-
Objective of the work: What is the goal of the paper? Is it to better address a known application or problem, draw attention to a new application or problem, or to introduce and/or explain a new theoretical finding? A combination of these? Different objectives will require different considerations as to potential value and impact.
-
Strong points: is the submission clear, technically correct, experimentally rigorous, reproducible, does it present novel findings (e.g. theoretically, algorithmically, etc.)?
-
Weak points: is it weak in any of the aspects listed in b.?
-
Be mindful of potential biases and try to be open-minded about the value and interest a paper can hold for the entire ICLR community, even if it may not be very interesting for you.
-
-
Answer three key questions for yourself, to make a recommendation to Accept or Reject:
-
What is the specific question and/or problem tackled by the paper?
-
Is the approach well motivated, including being well-placed in the literature?
-
Does the paper support the claims? This includes determining if results, whether theoretical or empirical, are correct and if they are scientifically rigorous.
-
-
Write your initial review, organizing it as follows:
-
Summarize what the paper claims to contribute. Be positive and generous.
-
List strong and weak points of the paper. Be as comprehensive as possible.
-
Clearly state your recommendation (accept or reject) with one or two key reasons for this choice.
-
Provide supporting arguments for your recommendation.
-
Ask questions you would like answered by the authors to help you clarify your understanding of the paper and provide the additional evidence you need to be confident in your assessment.
-
Provide additional feedback with the aim to improve the paper. Make it clear that these points are here to help, and not necessarily part of your decision assessment.
-
-
General points to consider:
-
Be polite in your review. Ask yourself whether you’d be happy to receive a review like the one you wrote.
-
Be precise and concrete. For example, include references to back up any claims, especially claims about novelty and prior work
-
Provide constructive feedback.
-
It’s also fine to explicitly state where you are uncertain and what you don’t quite understand. The authors may be able to resolve this in their response.
-
Don’t reject a paper just because you don’t find it “interesting”. This should not be a criterion at all for accepting/rejecting a paper. The research community is so big that somebody will find some value in the paper (maybe even a few years down the road), even if you don’t see it right now.
-
-
Complete the CoE report: ICLR has adopted the following Code of Ethics (CoE). Please check your assigned papers for conflicts with the code of ethics and mark them in your review form. If you are uncertain, please reach out to your area chair.
-
Engage in discussion: During the discussion phase, reviewers, authors and area chairs engage in asynchronous discussion, and authors are allowed to revise their submissions to address concerns that arise. It is crucial that you are actively engaged and responsive during this phase, i.e., you should be able to respond to comments/requests within 3 business days.
-
Provide final recommendation: Update your review, taking into account the new information collected during the discussion phase, and any revisions to the submission. Maintain a spirit of openness to changing your initial recommendation (either to a more positive or more negative) rating.
For great in-depth resources on reviewing, see these resources:
-
Daniel Dennet, Criticising with Kindness.
-
Comprehensive advice: Mistakes Reviewers Make
-
Views from multiple reviewers: Last minute reviewing advice
-
Perspective from instructions to Area Chairs: Dear ACs.
FAQ
Q: How should I use supplementary material?
A: It is not necessary to read supplementary material but such material can often answer questions that arise while reading the main paper, so consider looking there before asking authors.
Q: How should I handle a policy violation?
A: To flag a CoE violation related to a submission, please indicate it when submitting the CoE report for that paper. The AC will work with the PC and the ethics board to resolve the case. To discuss other violations (e.g. plagiarism, double submission, paper length, formatting, etc.), please contact either the AC or the PC as appropriate. You can do this by sending an official comment with the appropriate readership restrictions.
Q: How can I contact the AC for a paper?
A: To contact the AC for a paper: (i) go to the OpenReview page for that paper (while being logged into OpenReview); (ii) click the button to add an official comment and fill out the comment form; (iii) add the ACs to the list of "Readers".
Q: Am I allowed to ask for additional experiments?
A: You can ask for additional experiments, but make sure you justify why they’re necessary to push the paper over the acceptance threshold. New experiments should not significantly change the content of the submission. Rather, they should be limited in scope and serve to more thoroughly validate existing results from the submission.
Q: If a submission does not achieve state-of-the-art results, is that grounds for rejection?
A: No, a lack of state-of-the-art results does not by itself constitute grounds for rejection. Submissions bring value to the ICLR community when they convincingly demonstrate new, relevant, impactful, or insightful knowledge. Submissions can achieve this without achieving state-of-the-art results.
Q: Are authors expected to cite and compare with very recent work? What about non peer-reviewed (e.g., ArXiv) papers?
A: We consider papers contemporaneous if they are published (available in online proceedings) within the last four months. That means, since our full paper deadline is October 5, if a paper was published (i.e., at a peer-reviewed venue) on or after June 5, 2021, authors are not required to compare their own work to that paper. Authors are encouraged to cite and discuss all relevant papers, but they may be excused for not knowing about papers not published in peer-reviewed conference proceedings or journals, which includes papers exclusively available on arXiv. Reviewers are encouraged to use their own good judgement and, if in doubt, discuss with their area chair.
Q: How can I avoid being assigned papers that present a conflict of interest?
A: Conflicts of interest are detected using your OpenReview profile information (co-authors, past and current institutions, etc.). Therefore, the best way to avoid conflicts of interest is to update your OpenReview profile. If, while bidding, you come across a paper that presents a conflict of interest, please bid "Very Low" for that paper. If you are assigned a paper that presents a conflict of interest, please contact the program chairs immediately to have that paper re-assigned.
Review examples
Below are two reviews, copied verbatim from previous ICLR conferences, that adhere well to our guidelines above: one for an "Accept" recommendation, and the other for a "Reject" recommendation. Note that while each review is formatted differently according to each reviewer's style, both reviews are well-structured and therefore easy to navigate.
Example 1: Recommendation to accept
##########################################################################
Summary:
The paper provides an interesting direction in the meta-learning field. In particular, it proposes to enhance meta learning performance by fully exploring relations across multiple tasks. To capture such information, the authors develop a heterogeneity-aware meta-learning framework by introducing a novel architecture--meta-knowledge graph, which can dynamically find the most relevant structure for new tasks.
##########################################################################
Reasons for score:
Overall, I vote for accepting. I like the idea of mining the relation between tasks and handle it by the proposed meta-knowledge graph. My major concern is about the clarity of the paper and some additional ablation models (see cons below). Hopefully the authors can address my concern in the rebuttal period.
##########################################################################Pros:
1. The paper takes one of the most important issues of meta-learning: task heterogeneity. For me, the problem itself is real and practical.
2. The proposed meta-knowledge graph is novel for capturing the relation between tasks and address the problem of task heterogeneity. Graph structure provides a more flexible way of modeling relations. The design for using the prototype-based relational graph to query the meta-knowledge graph is reasonable and interesting.
3. This paper provides comprehensive experiments, including both qualitative analysis and quantitative results, to show the effectiveness of the proposed framework. The newly constructed Art-Multi dataset further enhances the difficulty of tasks and makes the performance more convincing.
##########################################################################
Cons:
1. Although the proposed method provides several ablation studies, I still suggest the authors to conduct the following ablation studies to enhance the quality of the paper:
(1) It might be valuable to investigate the modulation function. In the paper, the authors compare sigmoid, tanh, and Film layer. Can the authors analyze the results by reducing the number of gating parameters in Eq. 10 by sharing the gate value of each filter in Conv layers?
(2) What is the performance of the proposed model by changing the type of aggregators?
2. For the autoencoder aggregator, it would be better to provide more details about it, which seems not very clear to me.
3. In the qualitative analysis (i.e., Figure 2 and Figure 3), the authors provide one visualization for each task. It would be more convincing if the authors can provide more cases in the rebuttal period.
##########################################################################
Questions during rebuttal period:
Please address and clarify the cons above
#########################################################################
Some typos:
(1) Table 7: I. no sample-level graph -> I. no prototype-based graph
(2) 5.1 Hyperparameter Settings: we try both sigmoid, tanh Film -> we try both sigmoid, tanh, Film.
(3) parameteric -> parametric
(4) Table 2: Origninal -> original
(5) Section 4 first paragraph: The enhanced prototype representation -> The enhanced prototype representations
Updates: Thanks for the authors' response. The newly added experimental results address my concerns. I believe this paper will provide new insights for this field and I recommend this paper to be accepted.
Example 2: Recommendation to reject
Review: This paper proposes Recency Bias, an adaptive mini batch selection method for training deep neural networks. To select informative minibatches for training, the proposed method maintains a fixed size sliding window of past model predictions for each data sample. At a given iteration, samples which have highly inconsistent predictions within the sliding window are added to the minibatch. The main contribution of this paper is the introduction of a sliding window to remember past model predictions, as an improvement over the SOTA approach: Active Bias, which maintains a growing window of model predictions. Empirical studies are performed to show the superiority of Recency Bias over two SOTA approaches. Results are shown on the task of (1) image classification from scratch and (2) image classification by fine-tuning pretrained networks.
+ves:
+ The idea of using a sliding window over a growing window in active batch selection is interesting.
+ Overall, the paper is well written. In particular, the Related Work section has a nice flow and puts the proposed method into context. Despite the method having limited novelty (sliding window instead of a growing window), the method has been well motivated by pointing out the limitations in SOTA methods.
+ The results section is well structured. It's nice to see hyperparameter tuning results; and loss convergence graphs in various learning settings for each dataset.
Concerns:
- The key concern about the paper is the lack of rigorous experimentation to study the usefulness of the proposed method. Despite the paper stating that there have been earlier work (Joseph et al., 2019 and Wang et al., 2019) that attempt mini-batch selection, the paper does not compare with them. This is limiting. Further, since the proposed method is not specific to the domain of images, evaluating it on tasks other than image classification, such as text classification for instance, would have helped validate its applicability across domains.
- Considering the limited results, a deeper analysis of the proposed method would have been nice. The idea of a sliding window over a growing window is a generic one, and there have been many efforts to theoretically analyze active learning over the last two decades. How does the proposed method fit in there? (For example, how does the expected model variance change in this setting?) Some form of theoretical/analytical reasoning behind the effectiveness of recency bias (which is missing) would provide greater insights to the community and facilitate further research in this direction.
- The claim of 20.5% reduction in test error mentioned in the abstract has not been clearly addressed and pointed out in the results section of the paper.
- On the same note, the results are not conclusively in favor of the proposed method, and only is marginally better than the competitors. Why does online batch perform consistently than the proposed method? There is no discussion of these inferences from the results.
- The results would have been more complete if results were shown in a setting where just recency bias is used without the use of the selection pressure parameter. In other words, an ablation study on the effect of the selection pressure parameter would have been very useful.
- How important is the warm-up phase to the proposed method? Considering the paper states that this is required to get good estimates of the quantization index of the samples, some ablation studies on reducing/increasing the warm-up phase and showing the results would have been useful to understand this.
- Fig 4: Why are there sharp dips periodically in all the graphs? What do these correspond to?
- The intuition behind the method is described well, however, the proposed method would have been really solidified if it were analysed in the context of a simple machine learning problem (such as logistic regression). As an example, verifying if the chosen minibatch samples are actually close to the decision boundary of a model (even if the model is very simple) would have helped analyze the proposed method well.
Minor comments:
* It would have been nice to see the relation between the effect of using recency bias and the difficulty of the task/dataset.
* In the 2nd line in Introduction, it should be "deep networks" instead of "deep networks netowrks".
* Since both tasks in the experiments are about image classification, it would be a little misleading to present them as "image classification" and "finetuning". A more informative way of titling them would be "image classification from scratch" and "image classification by finetuning".
* In Section 3.1, in the LHS of equation 3, it would be appropriate to use P(y_i/x_i; q) instead of P(y/x_i; q) since the former term was used in the paragraph.
=====POST-REBUTTAL COMMENTS========
I thank the authors for the response and the efforts in the updated draft. Some of my queries were clarified. However, unfortunately, I still think more needs to be done to explain the consistency of the results and to study the generalizability of this work across datasets. I retain my original decision for these reasons.