Self-Generating Data for Goal-Conditioned Compositional Problems
{kind=link}
Abstract
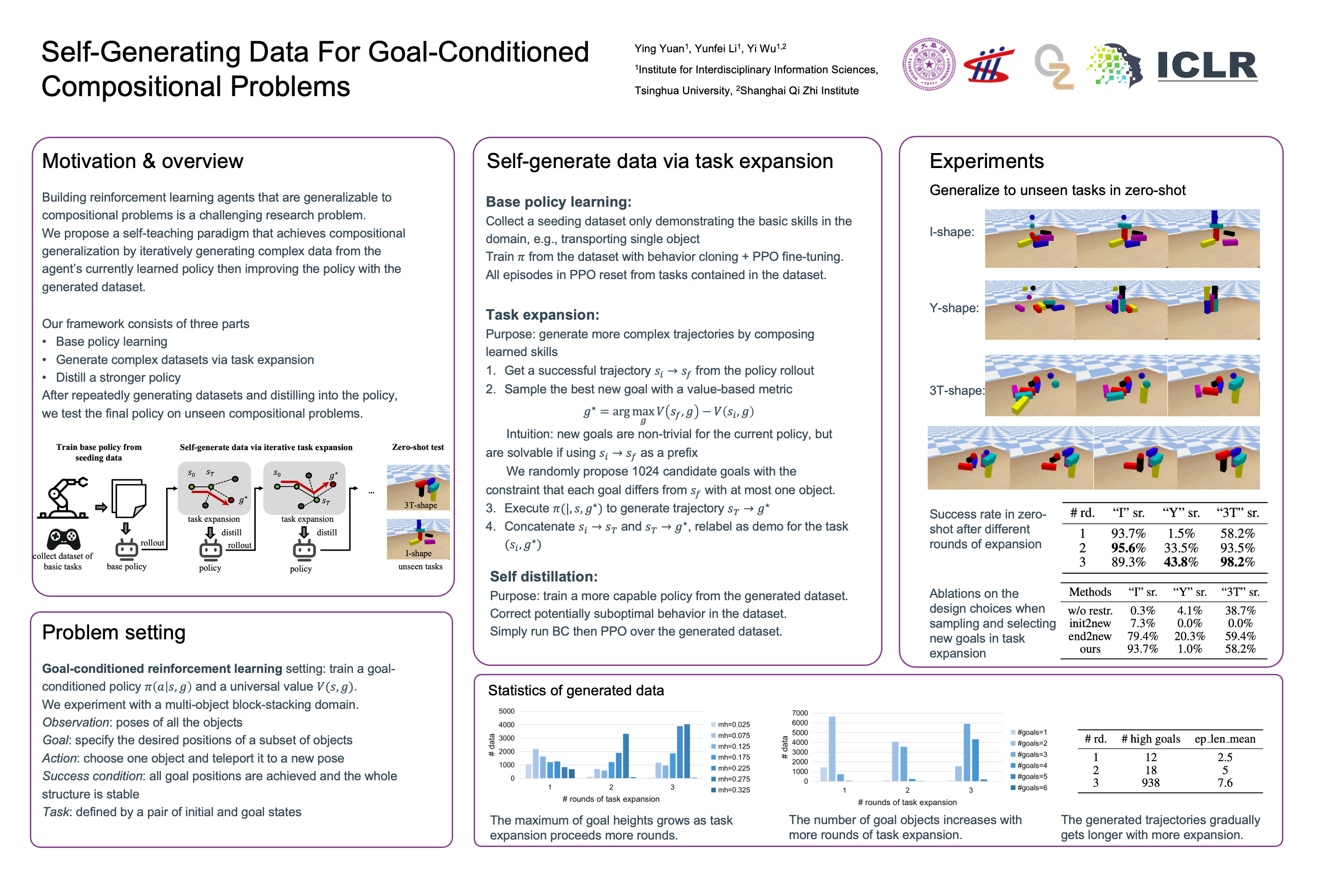
Building reinforcement learning agents that are generalizable to compositional problems has long been a research challenge. Recent success relies on a pre-existing dataset of rich behaviors. We present a novel paradigm to learn policies generalizable to compositional tasks with self-generated data. After learning primitive skills, the agent runs task expansion that actively expands out more complex tasks by composing learned policies and also naturally generates a dataset of demonstrations for self-distillation. In a proof-of-concept block-stacking environment, our agent discovers a large number of complex tasks after multiple rounds of data generation and distillation, and achieves an appealing zero-shot generalization success rate when building human-designed shapes.