Using Multimodal DNNs to Localize Vision-Language Integration in the Brain
in
Workshop: Multimodal Representation Learning (MRL): Perks and Pitfalls
{kind=link}
Abstract
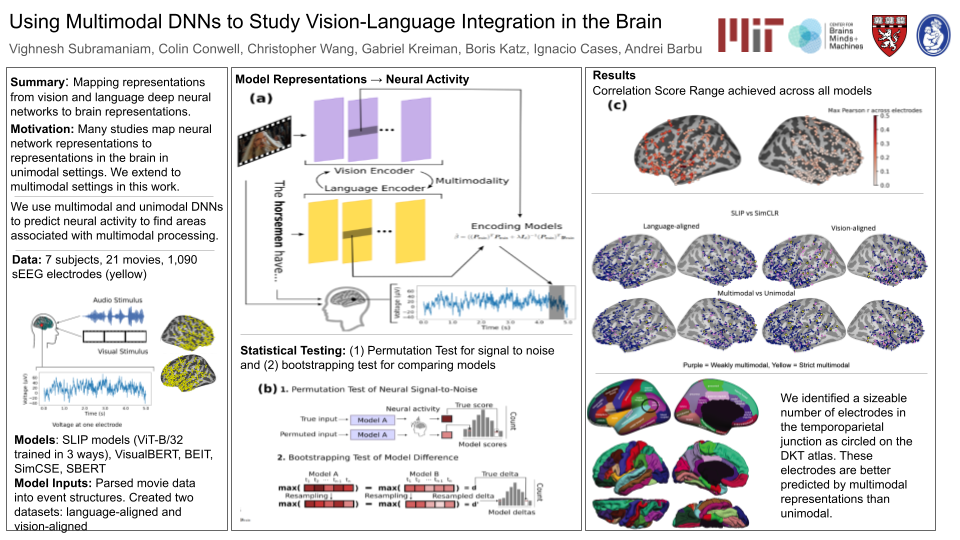
We leverage a large electrocorticography dataset consisting of neural recordings in response to movie viewing and a battery of unimodal and multimodal deep neural network models (SBERT, BEIT, SIMCLR, CLIP, SLIP) to identify candidate sites of multimodal integration in the human brain. Our data-driven method involves three steps: first, we parse the neural data into distinct event-structures defined either by word onset times, or visual scene cuts. We then use the activity generated by these event-structures in our candidate models to predict the activity generated in the brain. Finally, using contrasts between models with or without multimodal learning signals, we isolate those neural arrays driven more by multimodal representations than by unimodal representations. Using this method, we identify a sizable set of candidate neural sites that our model predictions suggest are shaped by multimodality (from 3%-29%, depending on increasingly conservative statistical inclusion criteria). We note a meaningful cluster of these multimodal neurons in and around the temporoparietal junction, long theorized to be a hub of multimodal integration.