Multimodal Subtask Graph Generation from Instructional Videos
Yunseok Jang ⋅ Sungryull Sohn ⋅ Tiange Luo ⋅ Lajanugen Logeswaran ⋅ Moontae Lee ⋅ Honglak Lee
Keywords:
vision and language
subtask graph
insturctional video
graph generation
Inductive Logic Programming
2023 Poster
in
Workshop: Multimodal Representation Learning (MRL): Perks and Pitfalls
in
Workshop: Multimodal Representation Learning (MRL): Perks and Pitfalls
{kind=link}
Abstract
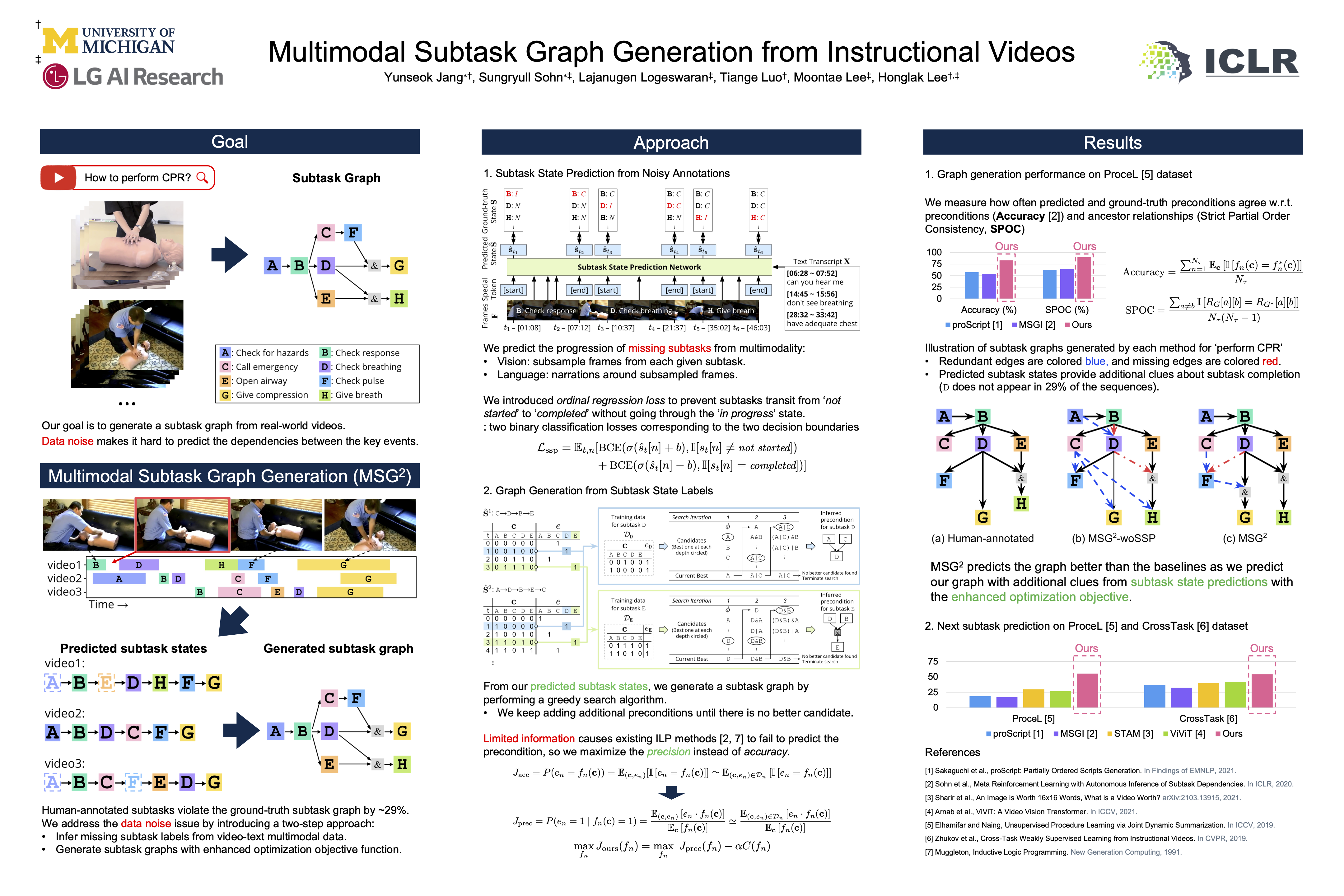
Real-world tasks consist of multiple inter-dependent subtasks (e.g., a dirty pan needs to be washed before cooking). In this work, we aim to model the causal dependencies between such subtasks from instructional videos describing the task. This is a challenging problem since complete information about the world is often inaccessible from videos, which demands robust learning mechanisms to understand the causal structure of events. We present Multimodal Subtask Graph Generation (MSG$^2$), an approach that constructs a Subtask Graph defining the dependency between a task’s subtasks relevant to a task from noisy web videos. Graphs generated by our multimodal approach are closer to human-annotated graphs compared to prior approaches. MSG$^2$ further performs the downstream task of next subtask prediction 85% and 30% more accurately than recent video transformer models in the ProceL and CrossTask datasets, respectively.
Video
Chat is not available.
Successful Page Load