[Remote poster] SlotDiffusion: Unsupervised Object-Centric Learning with Diffusion Models
{kind=link}
Abstract
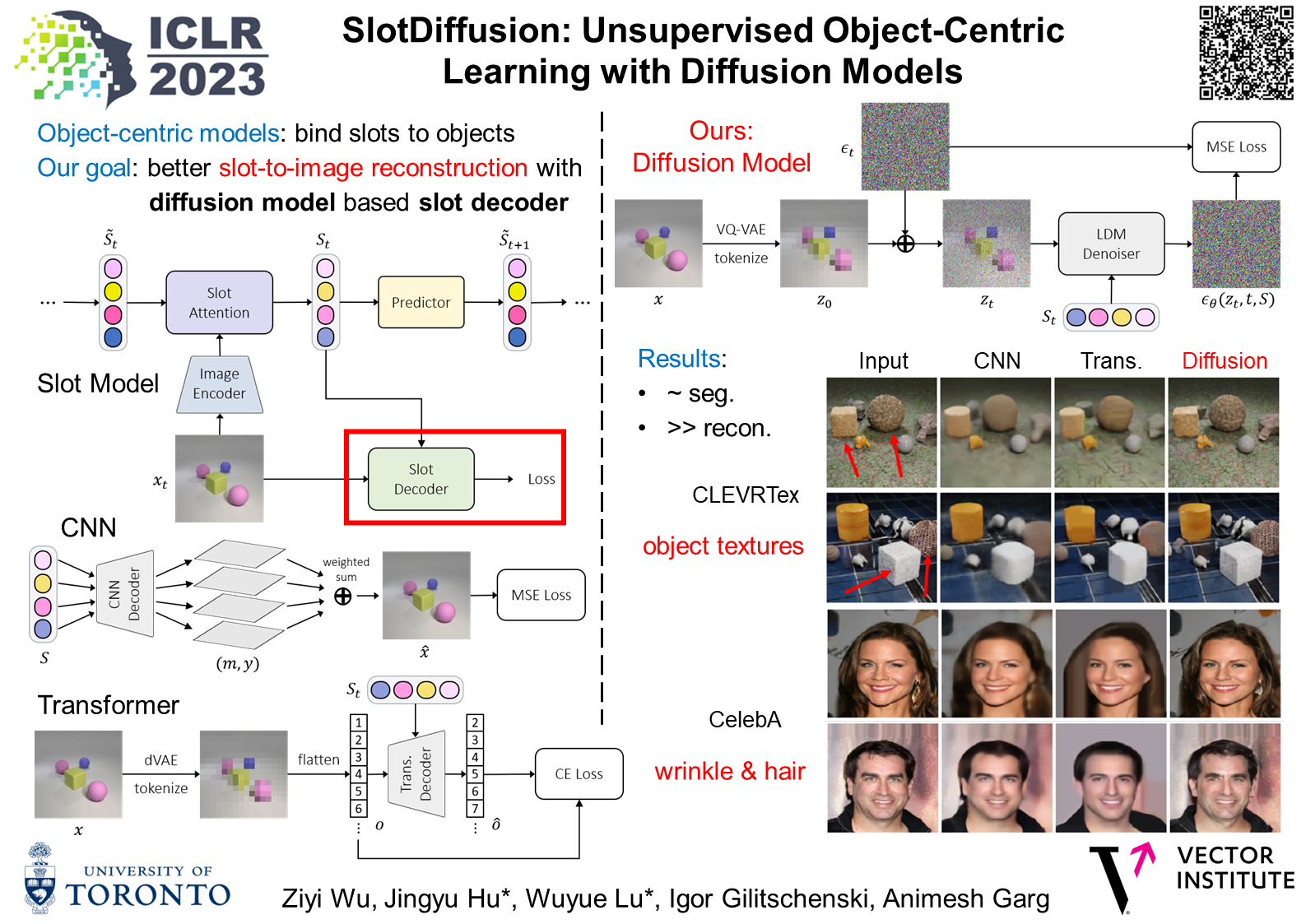
Object-centric learning aims to decompose the visual data into a set of individual entities, which is distinct from traditional deep learning models that represent a scene with a global feature. Leveraging advanced architectures such as Transformer decoders, slot-based models have shown promising results in unsupervised object discovery from naturalistic inputs. In this paper, we instead focus on the slot-to-image reconstruction quality of these models, a previously overlooked topic which is important for generation tasks such as video prediction and scene editing. Despite great segmentation outputs, recent unsupervised slot models produce blurry images and temporally inconsistent videos. We address this problem by introducing slot-conditioned diffusion models due to their strong generation capacity. Our proposed method, SlotDiffusion, not only achieves better unsupervised segmentation performance, but also generates results of higher quality compared to previous state-of-the-art on both image and video datasets.