LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning
Firas Al-Hafez ⋅ Davide Tateo ⋅ Oleg Arenz ⋅ Guoping Zhao ⋅ Jan Peters
Keywords:
inverse reinforcement learning
imitation learning
Reward Regularization
deep reinforcement learning
Reinforcement Learning
2023 In-Person Poster presentation / poster accept
{kind=link}
Abstract
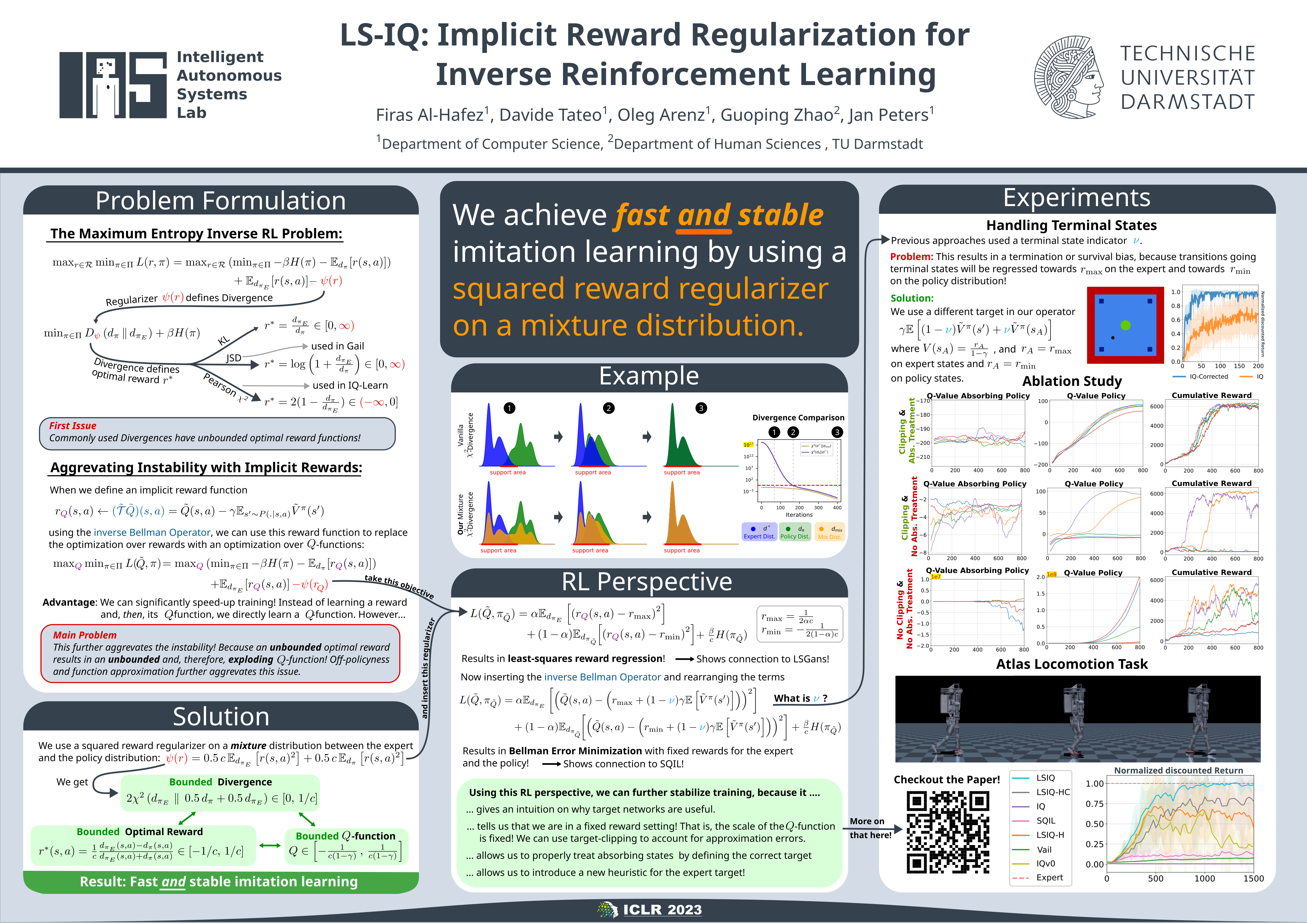
Recent methods for imitation learning directly learn a $Q$-function using an implicit reward formulation rather than an explicit reward function. However, these methods generally require implicit reward regularization to improve stability and often mistreat absorbing states. Previous works show that a squared norm regularization on the implicit reward function is effective, but do not provide a theoretical analysis of the resulting properties of the algorithms. In this work, we show that using this regularizer under a mixture distribution of the policy and the expert provides a particularly illuminating perspective: the original objective can be understood as squared Bellman error minimization, and the corresponding optimization problem minimizes a bounded $\chi^2$-Divergence between the expert and the mixture distribution. This perspective allows us to address instabilities and properly treat absorbing states. We show that our method, Least Squares Inverse Q-Learning (LS-IQ), outperforms state-of-the-art algorithms, particularly in environments with absorbing states. Finally, we propose to use an inverse dynamics model to learn from observations only. Using this approach, we retain performance in settings where no expert actions are available.
Video
Chat is not available.
Successful Page Load