Minimalistic Unsupervised Representation Learning with the Sparse Manifold Transform
Yubei Chen ⋅ Zeyu Yun ⋅ Yi Ma ⋅ Bruno Olshausen ⋅ Yann LeCun
Keywords:
unsupervised learning
manifold learning
Low-rank
Spectral Embedding
sparsity
Unsupervised and Self-supervised learning
2023 In-Person Poster presentation / top 25% paper
{kind=link}
Abstract
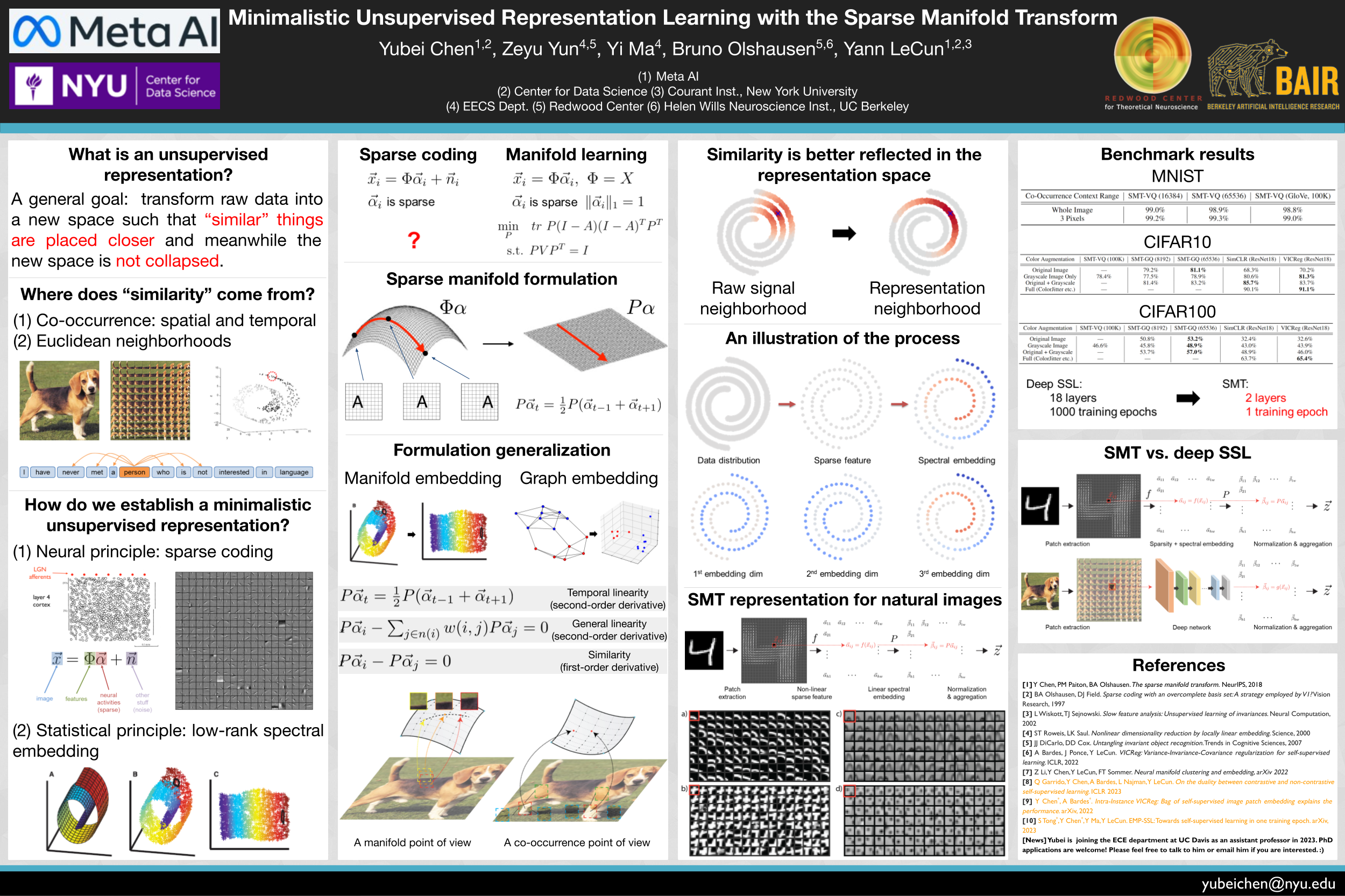
We describe a minimalistic and interpretable method for unsupervised representation learning that does not require data augmentation, hyperparameter tuning, or other engineering designs, but nonetheless achieves performance close to the state-of-the-art (SOTA) SSL methods. Our approach leverages the sparse manifold transform, which unifies sparse coding, manifold learning, and slow feature analysis. With a one-layer deterministic (one training epoch) sparse manifold transform, it is possible to achieve $99.3\%$ KNN top-1 accuracy on MNIST, $81.1\%$ KNN top-1 accuracy on CIFAR-10, and $53.2\%$ on CIFAR-100. With simple gray-scale augmentation, the model achieves $83.2\%$ KNN top-1 accuracy on CIFAR-10 and $57\%$ on CIFAR-100. These results significantly close the gap between simplistic ``white-box'' methods and SOTA methods. We also provide visualization to illustrate how an unsupervised representation transform is formed. The proposed method is closely connected to latent-embedding self-supervised methods and can be treated as the simplest form of VICReg. Though a small performance gap remains between our simple constructive model and SOTA methods, the evidence points to this as a promising direction for achieving a principled and white-box approach to unsupervised representation learning, which has potential to significantly improve learning efficiency.
Video
Chat is not available.
Successful Page Load