A new characterization of the edge of stability based on a sharpness measure aware of batch gradient distribution
Sungyoon Lee ⋅ Cheongjae Jang
Keywords:
implicit bias
generalization
implicit regularization
edge of stability
scaling rule
sharpness
optimization
batch size
learning rate
sgd
Theory
2023 In-Person Poster presentation / poster accept
{kind=link}
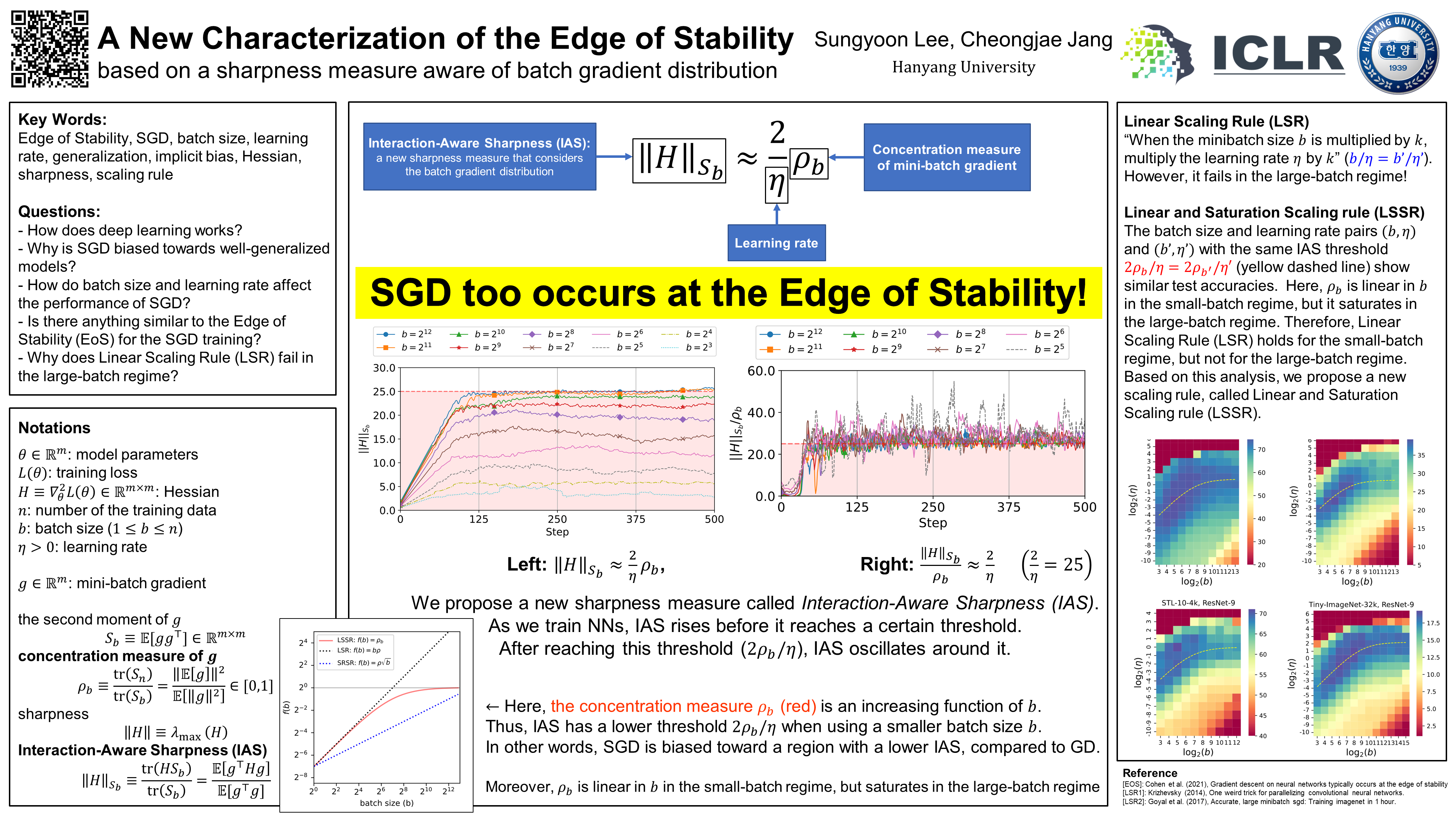
Abstract
For full-batch gradient descent (GD), it has been empirically shown that the sharpness, the top eigenvalue of the Hessian, increases and then hovers above $2/\text{(learning rate)}$, and this is called ``the edge of stability'' phenomenon. However, it is unclear why the sharpness is somewhat larger than $2/\text{(learning rate)}$ and how this can be extended to general mini-batch stochastic gradient descent (SGD). We propose a new sharpness measure (interaction-aware-sharpness) aware of the \emph{interaction} between the batch gradient distribution and the loss landscape geometry. This leads to a more refined and general characterization of the edge of stability for SGD. Moreover, based on the analysis of a concentration measure of the batch gradient, we propose a more accurate scaling rule, Linear and Saturation Scaling Rule (LSSR), between batch size and learning rate.
Video
Chat is not available.
Successful Page Load