Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
Jihwan Jeong ⋅ Xiaoyu Wang ⋅ Michael Gimelfarb ⋅ Hyunwoo Kim ⋅ Baher Abdulhai ⋅ Scott Sanner
Keywords:
bayesian inference
model-based value expansion
offline reinforcement learning
model-based reinforcement learning
Reinforcement Learning
2023 In-Person Poster presentation / poster accept
{kind=link}
Abstract
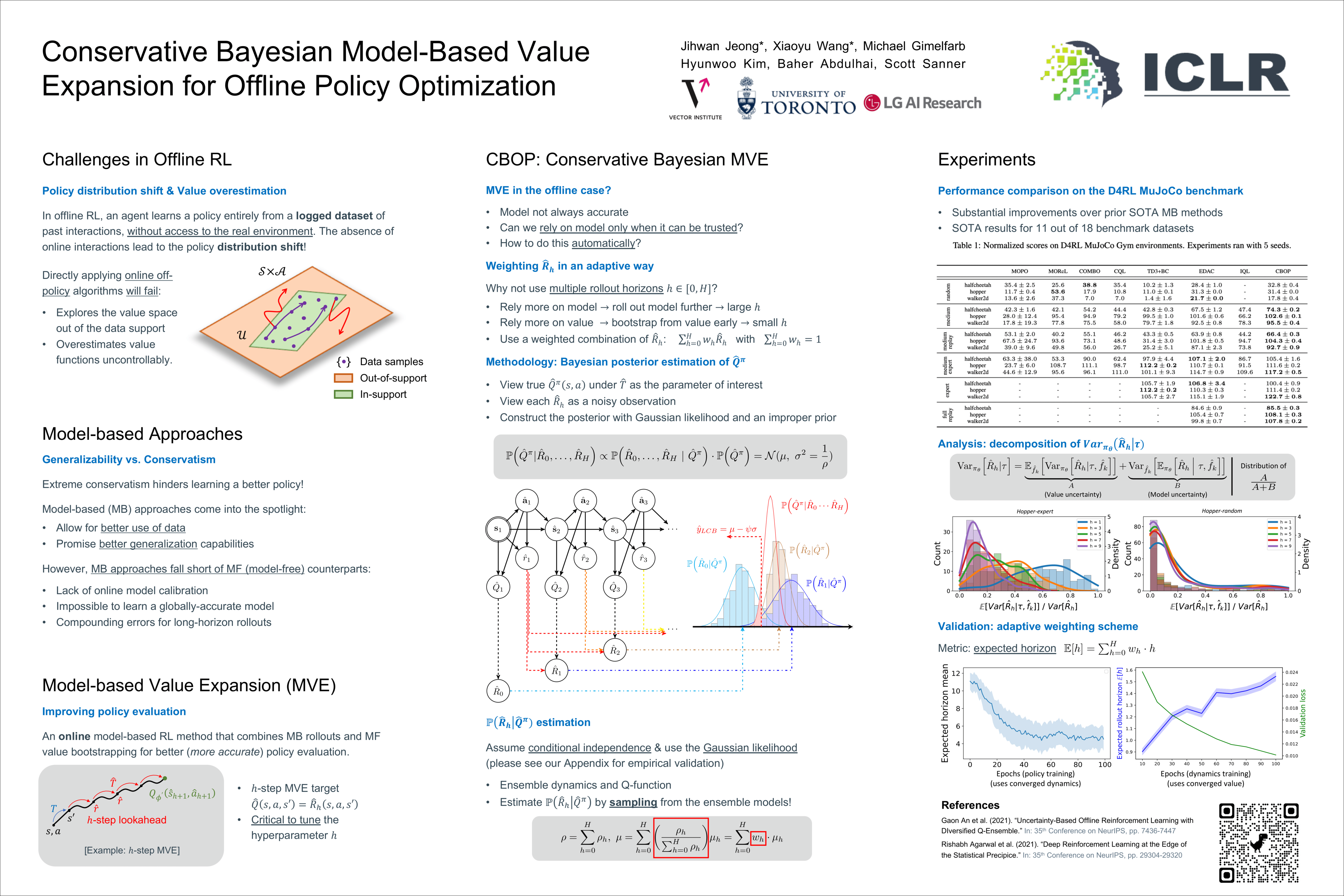
Offline reinforcement learning (RL) addresses the problem of learning a performant policy from a fixed batch of data collected by following some behavior policy. Model-based approaches are particularly appealing in the offline setting since they can extract more learning signals from the logged dataset by learning a model of the environment. However, the performance of existing model-based approaches falls short of model-free counterparts, due to the compounding of estimation errors in the learned model. Driven by this observation, we argue that it is critical for a model-based method to understand when to trust the model and when to rely on model-free estimates, and how to act conservatively w.r.t. both. To this end, we derive an elegant and simple methodology called conservative Bayesian model-based value expansion for offline policy optimization (CBOP), that trades off model-free and model-based estimates during the policy evaluation step according to their epistemic uncertainties, and facilitates conservatism by taking a lower bound on the Bayesian posterior value estimate. On the standard D4RL continuous control tasks, we find that our method significantly outperforms previous model-based approaches: e.g., MOPO by $116.4$%, MOReL by $23.2$% and COMBO by $23.7$%. Further, CBOP achieves state-of-the-art performance on $11$ out of $18$ benchmark datasets while doing on par on the remaining datasets.
Video
Chat is not available.
Successful Page Load