Sparse MoE as the New Dropout: Scaling Dense and Self-Slimmable Transformers
Tianlong Chen ⋅ Zhenyu Zhang ⋅ AJAY JAISWAL ⋅ Shiwei Liu ⋅ Zhangyang Wang
Keywords:
Transformer Training
Random Routing
Sparse Mixture-of-Experts
dropout
Deep Learning and representational learning
2023 In-Person Poster presentation / top 25% paper
{kind=link}
Abstract
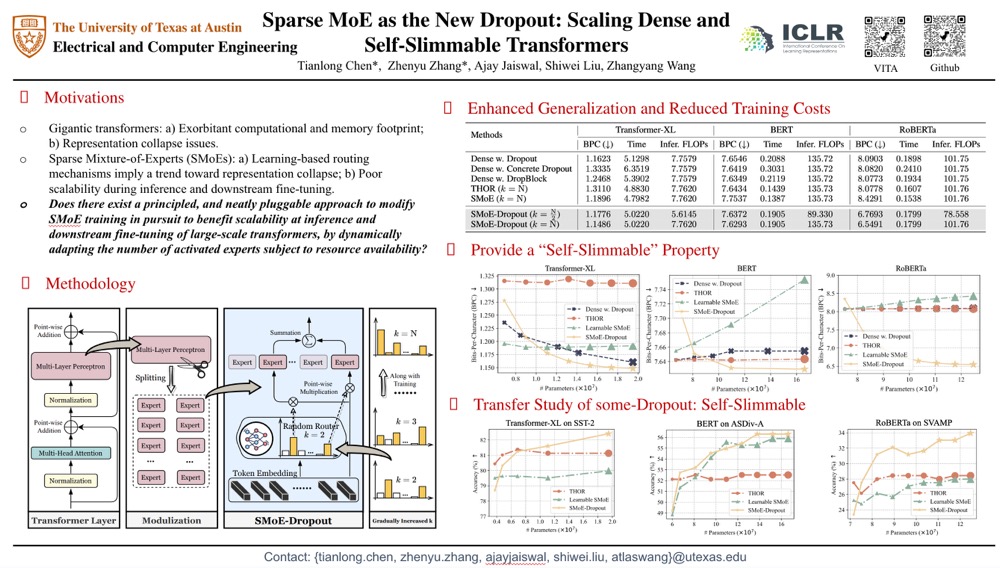
Despite their remarkable achievement, gigantic transformers encounter significant drawbacks, including exorbitant computational and memory footprints during training, as well as severe collapse evidenced by a high degree of parameter redundancy. Sparsely-activated Mixture-of-Experts (SMoEs) have shown promise to mitigate the issue of training efficiency, yet they are prone to (1) $\textit{redundant experts}$ due to representational collapse; and (2) $\textit{poor expert scalability for inference and downstream fine-tuning}$, primarily due to overfitting of the learned routing policy to the number of activated experts during training. As recent research efforts are predominantly focused on improving routing policies to encourage expert specializations, this work focuses on $\textit{exploring the overlooked scalability bottleneck of SMoEs}$ and leveraging it to effectively $\textbf{scale dense transformers}$. To this end, we propose a new plug-and-play training framework, $\textbf{SMoE-Dropout}$, to enable scaling transformers to better accuracy in their full capacity without collapse. Specifically, SMoE-Dropout consists of a $\textit{randomly initialized and fixed}$ router network to activate experts and gradually increases the activated expert number as training progresses over time. Transformers trained by SMoE-Dropout naturally exhibit a $\textbf{``self-slimmable”}$ property subject to resource availability, offering smooth and consistent performance boosts with an increase in activated experts during inference or fine-tuning. Our extensive experiments across diverse transformer architectures on a variety of tasks demonstrate the superior performance and substantial computation savings of SMoE-Dropout, compared to dense training baselines with equivalent parameter counts. In particular, our trained BERT outperforms its densely trained counterpart with consistent improvements of {$1.03\%$, $0.78\%$, $1.09\%$} on challenging reasoning tasks {$\texttt{ASDiv-A}$, $\texttt{MAWPS}$, $\texttt{SVAMP}$}, respectively. Codes and models are available in https://github.com/VITA-Group/Random-MoE-as-Dropout.
Video
Chat is not available.
Successful Page Load