Fewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
{kind=link}
Abstract
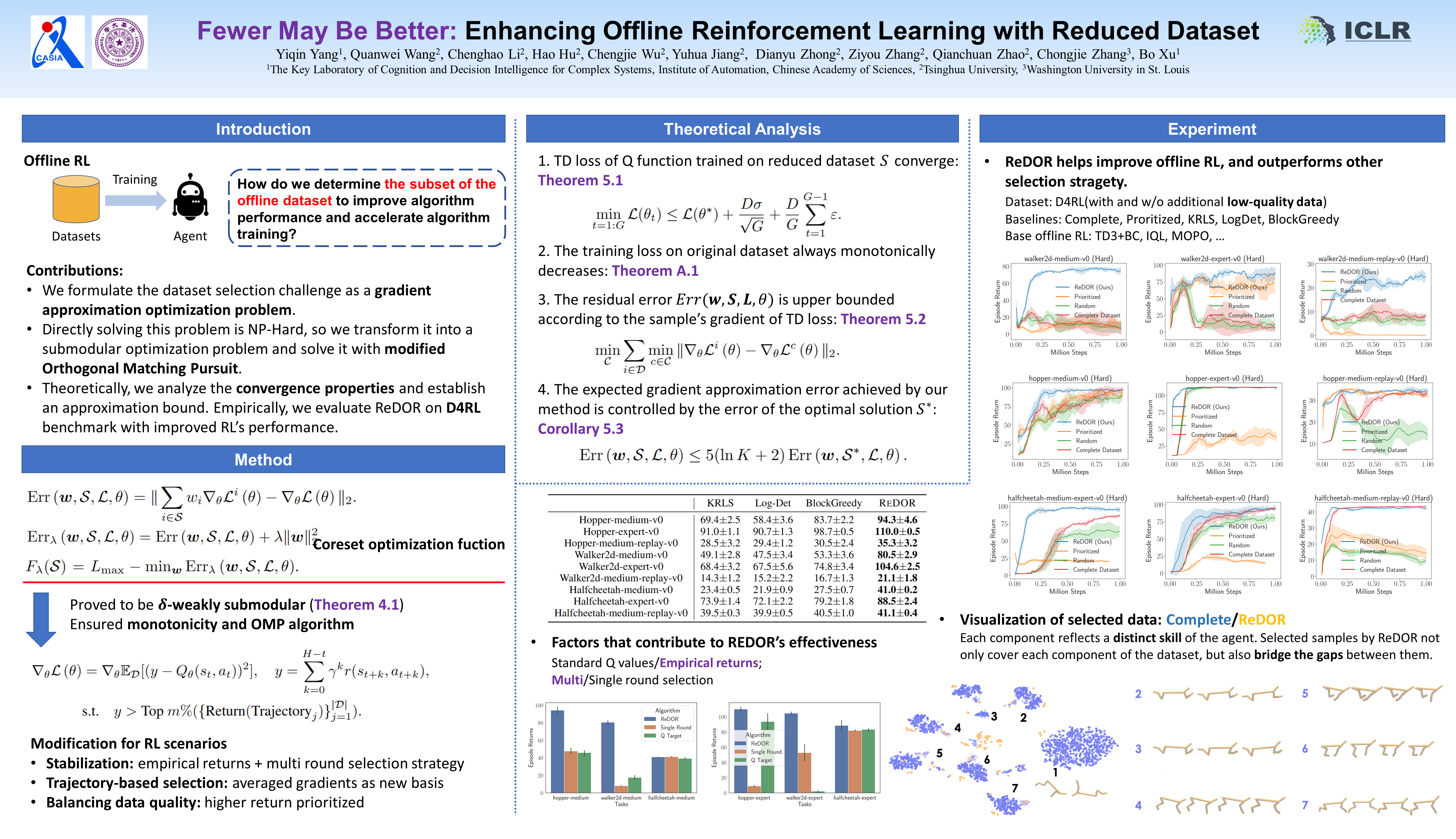
Research in offline reinforcement learning (RL) marks a paradigm shift in RL. However, a critical yet under-investigated aspect of offline RL is determining the subset of the offline dataset, which is used to improve algorithm performance while accelerating algorithm training. Moreover, the size of reduced datasets can uncover the requisite offline data volume essential for addressing analogous challenges. Based on the above considerations, we propose identifying Reduced Datasets for Offline RL (ReDOR) by formulating it as a gradient approximation optimization problem. We prove that the common actor-critic framework in reinforcement learning can be transformed into a submodular objective. This insight enables us to construct a subset by adopting the orthogonal matching pursuit (OMP). Specifically, we have made several critical modifications to OMP to enable successful adaptation with Offline RL algorithms. The experimental results indicate that the data subsets constructed by the ReDOR can significantly improve algorithm performance with low computational complexity.