Ultra-Sparse Memory Network
{kind=link}
Abstract
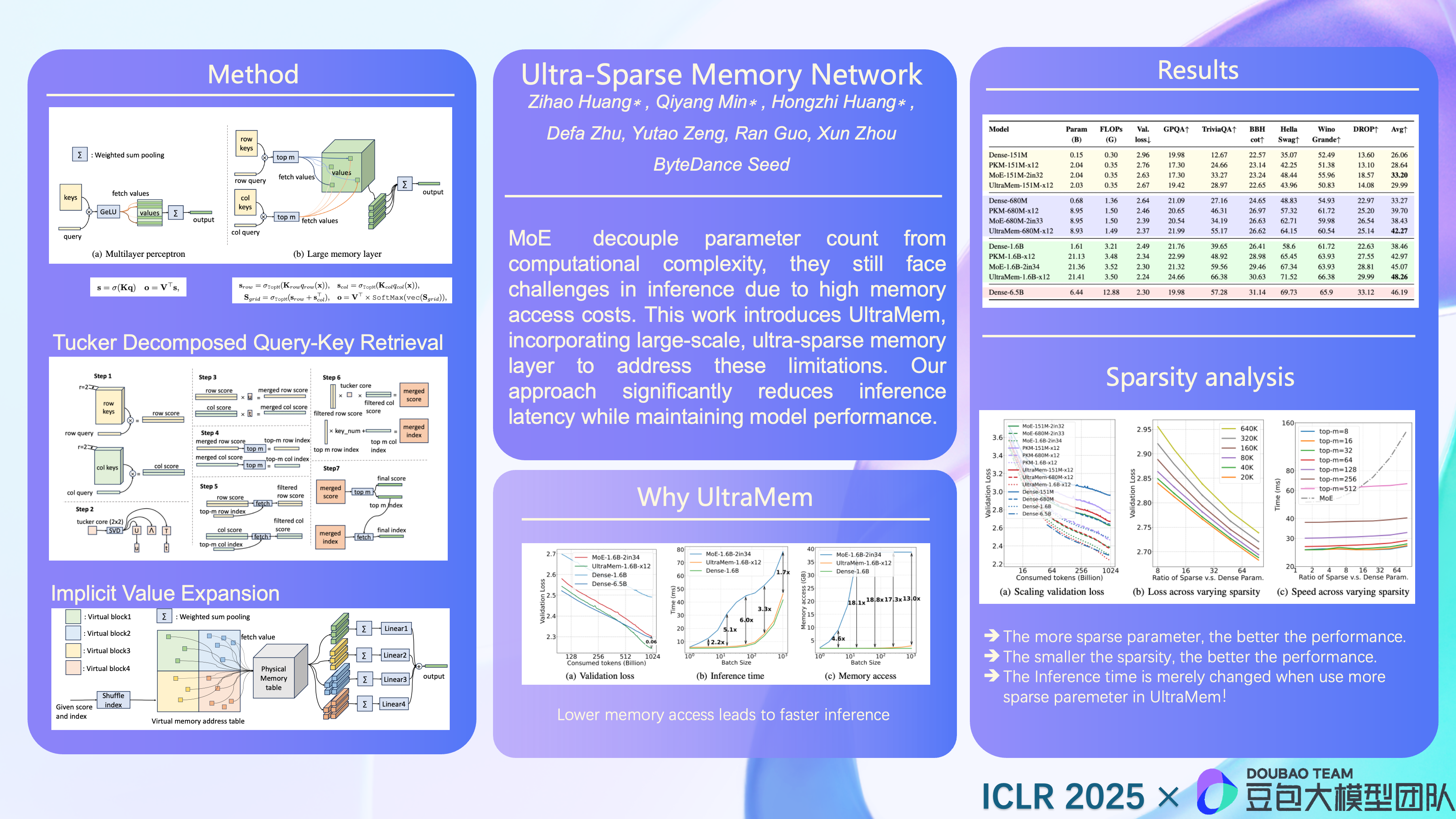
It is widely acknowledged that the performance of Transformer models is logarithmically related to their number of parameters and computational complexity. While approaches like Mixture of Experts (MoE) decouple parameter count from computational complexity, they still face challenges in inference due to high memory access costs. This work introduces UltraMem, incorporating large-scale, ultra-sparse memory layer to address these limitations. Our approach significantly reduces inference latency while maintaining model performance. We also investigate the scaling laws of this new architecture, demonstrating that it not only exhibits favorable scaling properties but outperforms MoE. In experiments, the largest UltraMem we train has \textbf{20 million} memory slots. The results show that our method achieves state-of-the-art inference speed and model performance within a given computational budget, paving the way for billions of slots or experts.