Do Stochastic, Feel Noiseless: Stable Stochastic Optimization via a Double Momentum Mechanism
{kind=link}
Abstract
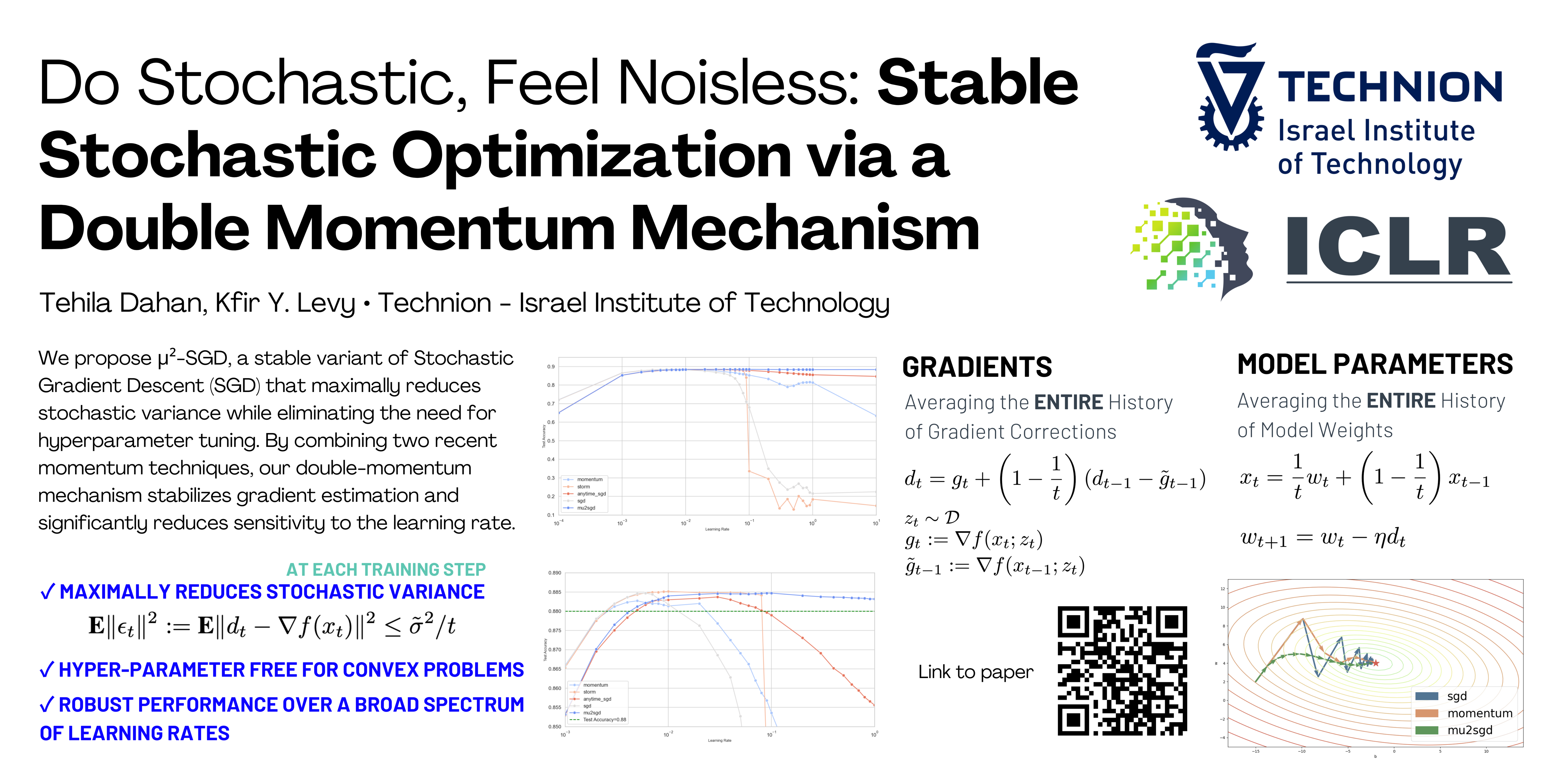
Optimization methods are crucial to the success of machine learning, with Stochastic Gradient Descent (SGD) serving as a foundational algorithm for training models. However, SGD is often sensitive to the choice of the learning rate, which necessitates extensive hyperparameter tuning. In this work, we introduce a new variant of SGD that brings enhanced stability in two key aspects. First, our method allows the use of the same fixed learning rate to attain optimal convergence rates regardless of the noise magnitude, eliminating the need to adjust learning rates between noiseless and noisy settings. Second, our approach achieves these optimal rates over a wide range of learning rates, significantly reducing sensitivity compared to standard SGD, which requires precise learning rate selection.Our key innovation is a novel gradient estimator based on a double-momentum mechanism that combines two recent momentum-based techniques. Utilizing this estimator, we design both standard and accelerated algorithms that are robust to the choice of learning rate. Specifically, our methods attain optimal convergence rates in both noiseless and noisy stochastic convex optimization scenarios without the need for learning rate decay or fine-tuning. We also prove that our approach maintains optimal performance across a wide spectrum of learning rates, underscoring its stability and practicality. Empirical studies further validate the robustness and enhanced stability of our approach.