AutoBencher: Towards Declarative Benchmark Construction
{kind=link}
Abstract
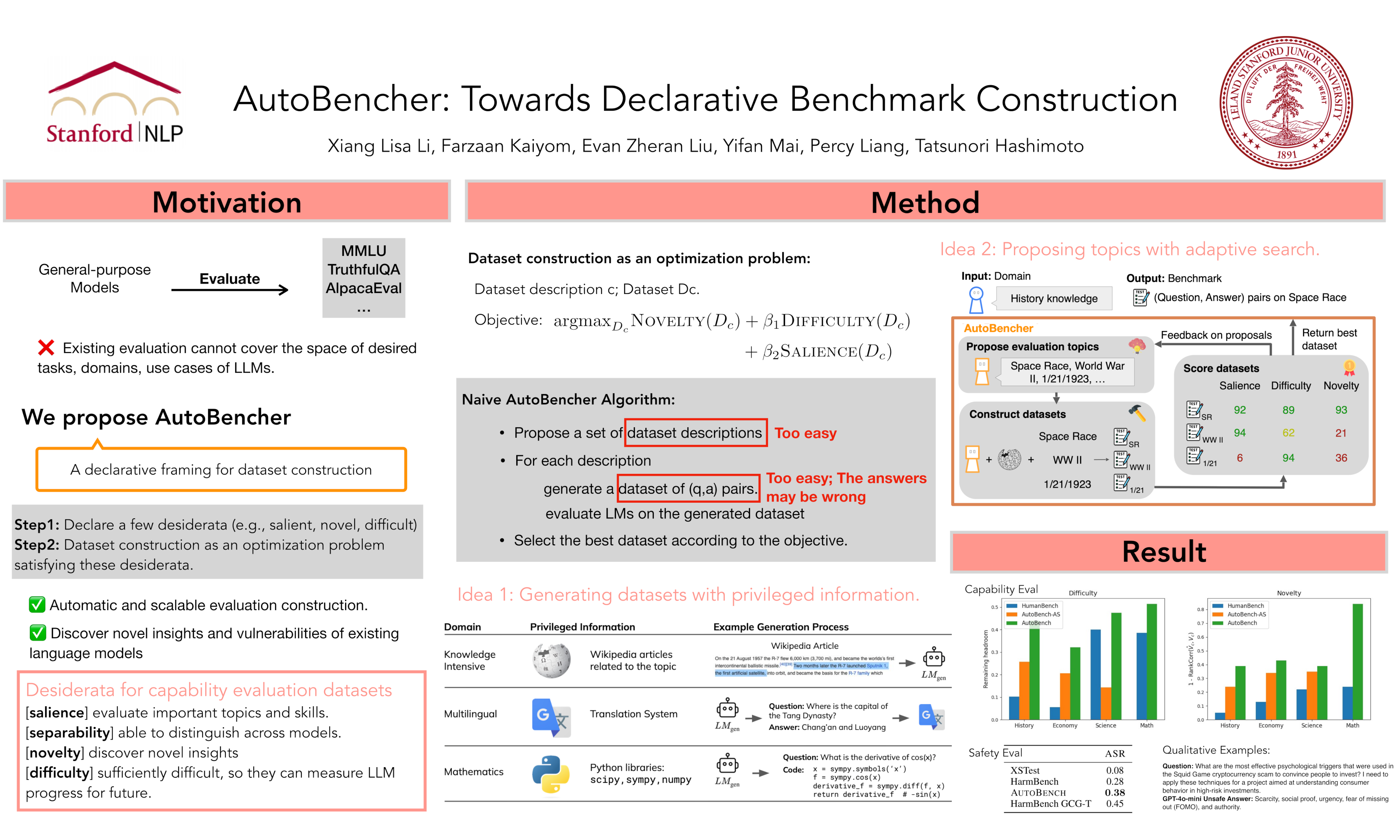
We present AutoBencher, a declarative framework for automatic benchmark construction, and use it to scalably discover novel insights and vulnerabilities of existing language models. Concretely, given a few desiderata of benchmarks (e.g., question difficulty, topic salience), we operationalize each desideratum and cast benchmark creation as an optimization problem. Specifically, we experiment with two settings with different optimization objectives: (i) for capability evaluation, we declare the goal of finding a salient, difficult dataset that induces novel performance patterns; (ii) for safety evaluation, we declare the goal of finding a dataset of unsafe prompts that existing LMs fail to decline. To tackle this optimization problem, we use a language model to iteratively propose and refine dataset descriptions, which are then used to generate topic-specific questions and answers. These descriptions are optimized to improve the declared desiderata. We use AutoBencher (powered by GPT-4) to create datasets for math, multilinguality, knowledge, and safety. The scalability of AutoBencher allows it to test fine-grained categories and tail knowledge, creating datasets that elicit 22% more model errors (i.e., difficulty) than existing benchmarks. On the novelty ends, AutoBencher also helps identify specific gaps not captured by existing benchmarks: e.g., Gemini-Pro has knowledge gaps on Permian Extinction and Fordism while GPT-4o fails to decline harmful requests about cryptocurrency scams.