OLMoE: Open Mixture-of-Experts Language Models
Niklas Muennighoff ⋅ Luca Soldaini ⋅ Dirk Groeneveld ⋅ Kyle Lo ⋅ Jacob Morrison ⋅ Sewon Min ⋅ Weijia Shi ⋅ Pete Walsh ⋅ Oyvind Tafjord ⋅ Nathan Lambert ⋅ Yuling Gu ⋅ Shane Arora ⋅ Akshita Bhagia ⋅ Dustin Schwenk ⋅ David Wadden ⋅ Alexander Wettig ⋅ Binyuan Hui ⋅ Tim Dettmers ⋅ Douwe Kiela ⋅ Ali Farhadi ⋅ Noah Smith ⋅ Pang Wei Koh ⋅ Amanpreet Singh ⋅ Hanna Hajishirzi
2025 Poster
{kind=link}
Abstract
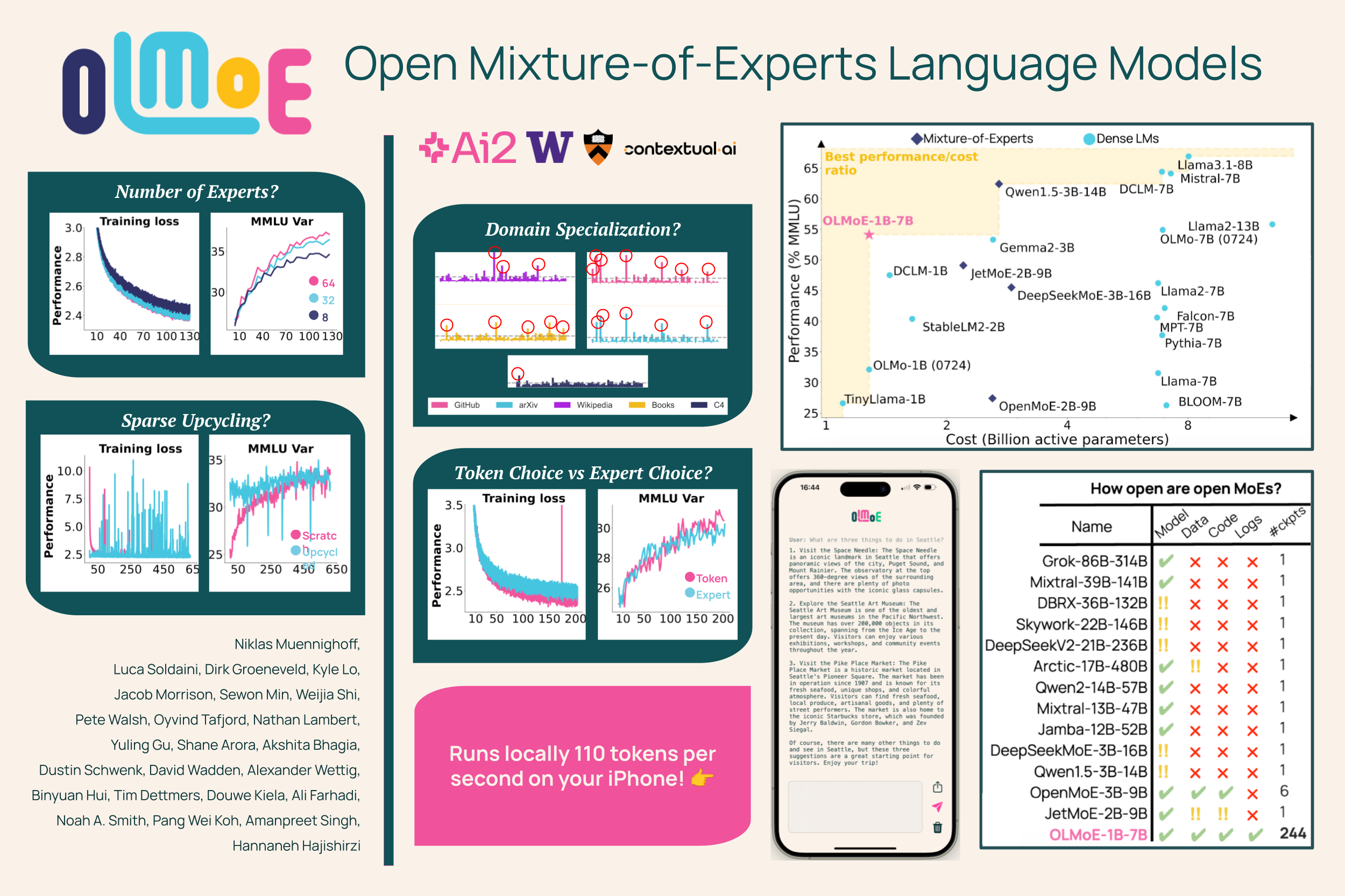
We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present novel findings on MoE training, define and analyze new routing properties showing high specialization in our model, and open-source all our work: model weights, training data, code, and logs.
Video
Chat is not available.
Successful Page Load