Efficient Low-Bit Quantization with Adaptive Scales for Multi-Task Co-Training
Boyu Liu ⋅ Haoyu Huang ⋅ Linlin Yang ⋅ Yanjing Li ⋅ Guodong Guo ⋅ Xianbin Cao ⋅ Baochang Zhang
2025 Poster
{kind=link}
Abstract
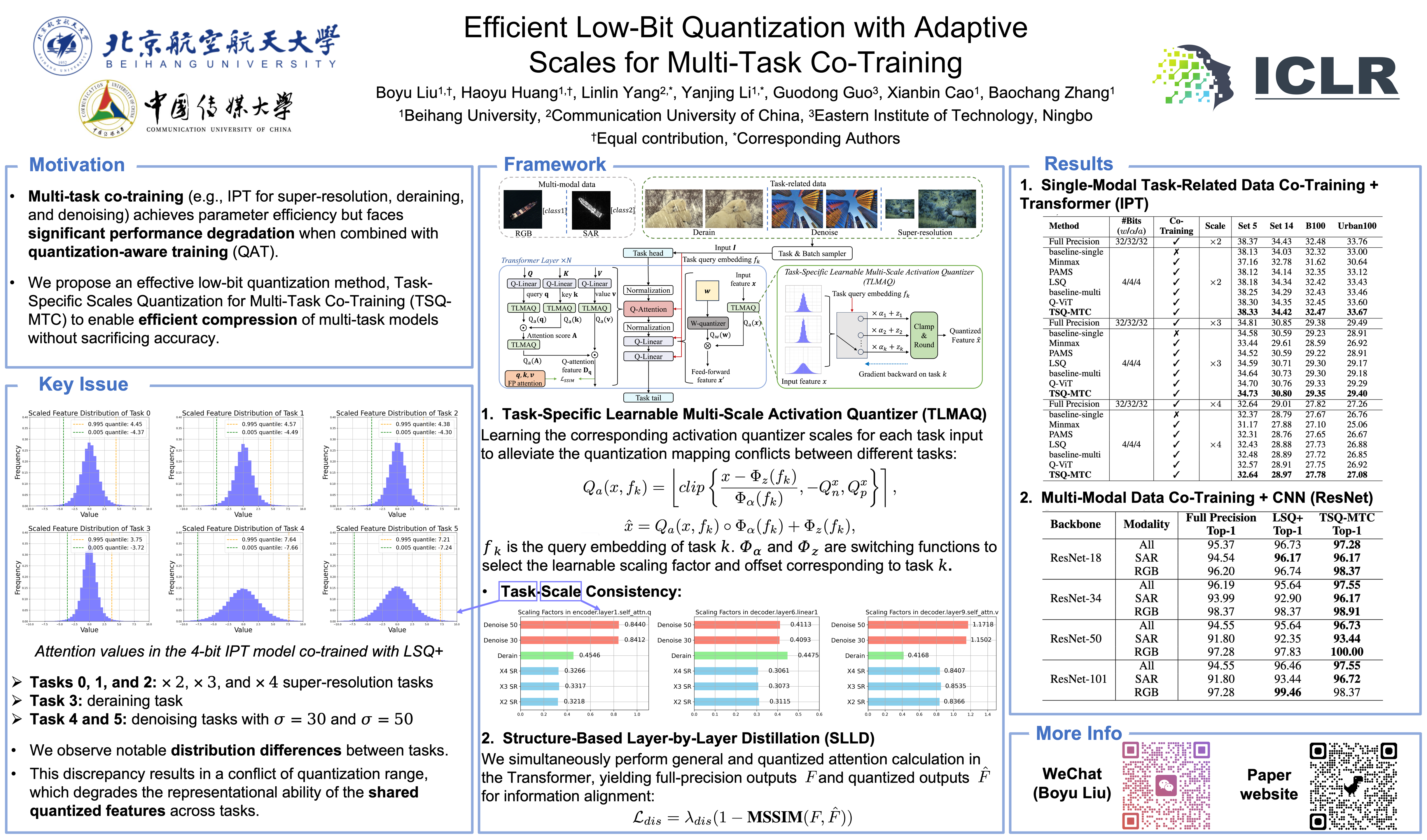
Co-training can achieve parameter-efficient multi-task models but remains unexplored for quantization-aware training. Our investigation shows that directly introducing co-training into existing quantization-aware training (QAT) methods results in significant performance degradation. Our experimental study identifies that the primary issue with existing QAT methods stems from the inadequate activation quantization scales for the co-training framework. To address this issue, we propose Task-Specific Scales Quantization for Multi-Task Co-Training (TSQ-MTC) to tackle mismatched quantization scales. Specifically, a task-specific learnable multi-scale activation quantizer (TLMAQ) is incorporated to enrich the representational ability of shared features for different tasks. Additionally, we find that in the deeper layers of the Transformer model, the quantized network suffers from information distortion within the attention quantizer. A structure-based layer-by-layer distillation (SLLD) is then introduced to ensure that the quantized features effectively preserve the information from their full-precision counterparts. Our extensive experiments in two co-training scenarios demonstrate the effectiveness and versatility of TSQ-MTC. In particular, we successfully achieve a 4-bit quantized low-level visual foundation model based on IPT, which attains a PSNR comparable to the full-precision model while offering a $7.99\times$ compression ratio in the $\times4$ super-resolution task on the Set5 benchmark.
Video
Chat is not available.
Successful Page Load