Param$\Delta$ for Direct Mixing: Post-Train Large Language Model At Zero Cost
Sheng Cao ⋅ Mingrui Wu ⋅ Karthik Prasad ⋅ Yuandong Tian ⋅ Zechun Liu
2025 Poster
{kind=link}
Abstract
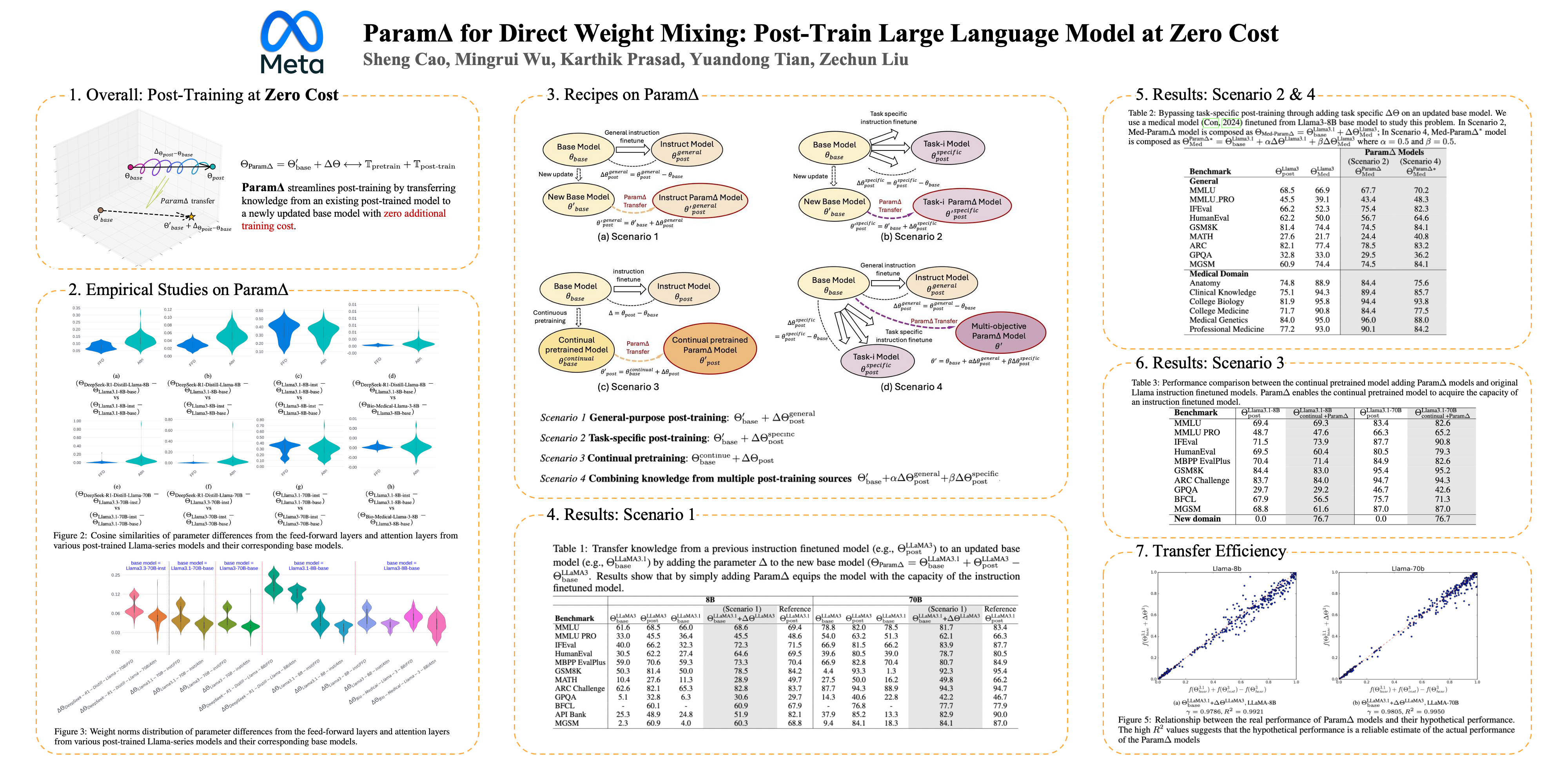
The post-training phase of large language models is essential for enhancing capabilities such as instruction-following, reasoning, and alignment with human preferences. However, it demands extensive high-quality data and poses risks like overfitting, alongside significant computational costs due to repeated post-training and evaluation after each base model update. This paper introduces Param$\Delta$, a novel method that streamlines post-training by transferring knowledge from an existing post-trained model to a newly updated base model with \textbf{zero} additional training. By computing the difference between post-trained model weights ($\Theta_\text{post}$) and base model weights ($\Theta_\text{base}$), and adding this to the updated base model ($\Theta_\text{base}'$), we define Param$\Delta$ Model as: $\Theta_{\text{Param}\Delta} = \Theta_\text{post} - \Theta_\text{base} + \Theta_\text{base}'$. This approach surprisingly equips the new base model with post-trained capabilities, achieving performance comparable to direct post-training. We did analysis on LLama3, Llama3.1, Qwen, and DeepSeek-distilled models. Results indicate Param$\Delta$ Model effectively replicates traditional post-training. For example, the Param$\Delta$ Model obtained from 70B Llama3-inst, Llama3-base, Llama3.1-base models attains approximately 95\% of Llama3.1-inst model's performance on average. Param$\Delta$ brings a new perspective on how to fully leverage models in the open-weight community, where checkpoints for base and instruct models are readily available and frequently updated, by providing a cost-free framework to accelerate the iterative cycle of model development.
Video
Chat is not available.
Successful Page Load