Deep Weight Factorization: Sparse Learning Through the Lens of Artificial Symmetries
Chris Kolb ⋅ Tobias Weber ⋅ Bernd Bischl ⋅ David Rügamer
2025 Poster
{kind=link}
Abstract
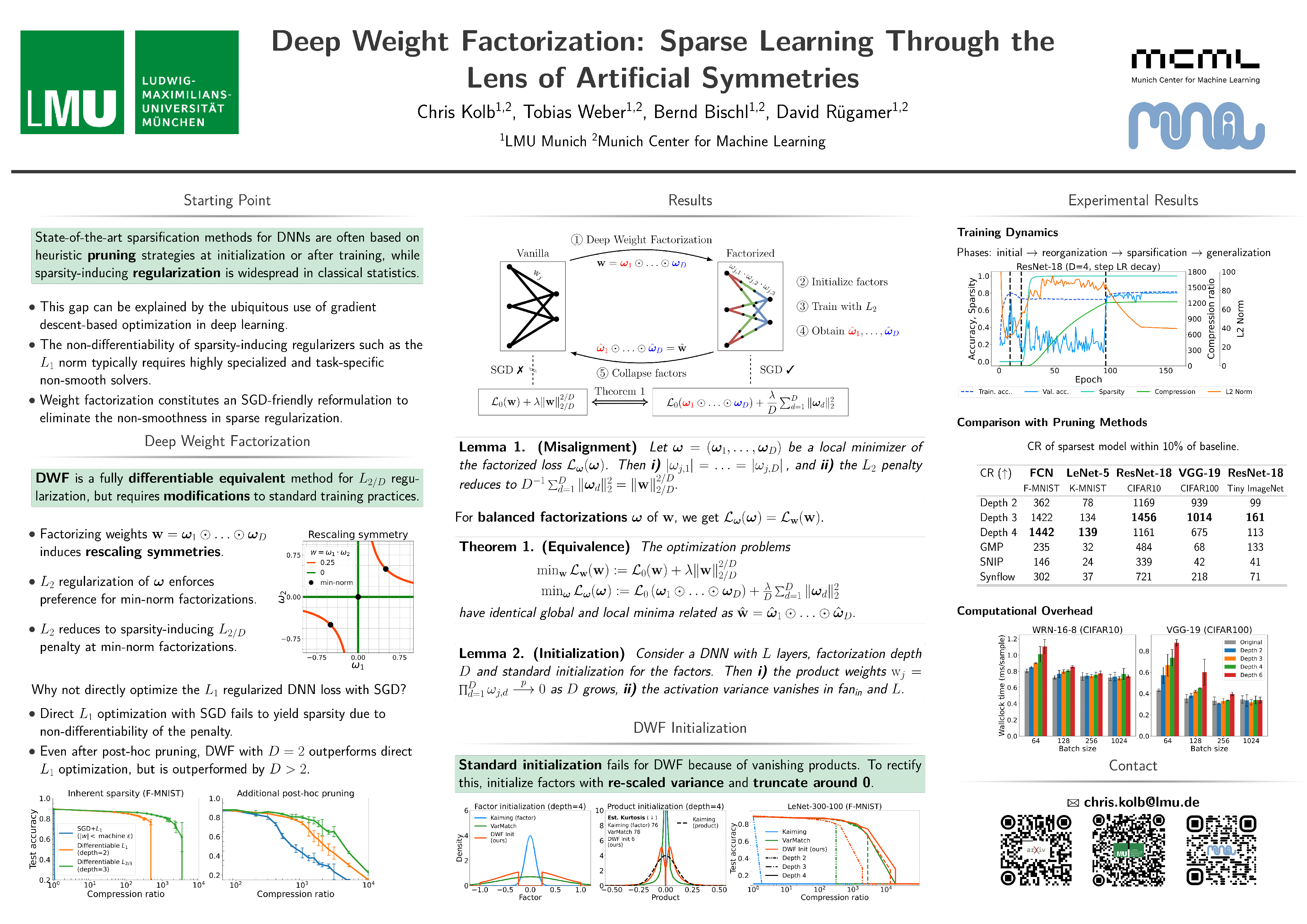
Sparse regularization techniques are well-established in machine learning, yet their application in neural networks remains challenging due to the non-differentiability of penalties like the $L_1$ norm, which is incompatible with stochastic gradient descent. A promising alternative is shallow weight factorization, where weights are decomposed into two factors, allowing for smooth optimization of $L_1$-penalized neural networks by adding differentiable $L_2$ regularization to the factors. In this work, we introduce deep weight factorization, extending previous shallow approaches to more than two factors. We theoretically establish equivalence of our deep factorization with non-convex sparse regularization and analyze its impact on training dynamics and optimization. Due to the limitations posed by standard training practices, we propose a tailored initialization scheme and identify important learning rate requirements necessary for training factorized networks.We demonstrate the effectiveness of our deep weight factorization through experiments on various architectures and datasets, consistently outperforming its shallow counterpart and widely used pruning methods.
Video
Chat is not available.
Successful Page Load