How Much is Unseen Depends Chiefly on Information About the Seen
Seongmin Lee ⋅ Marcel Boehme
2025 Poster
{kind=link}
Abstract
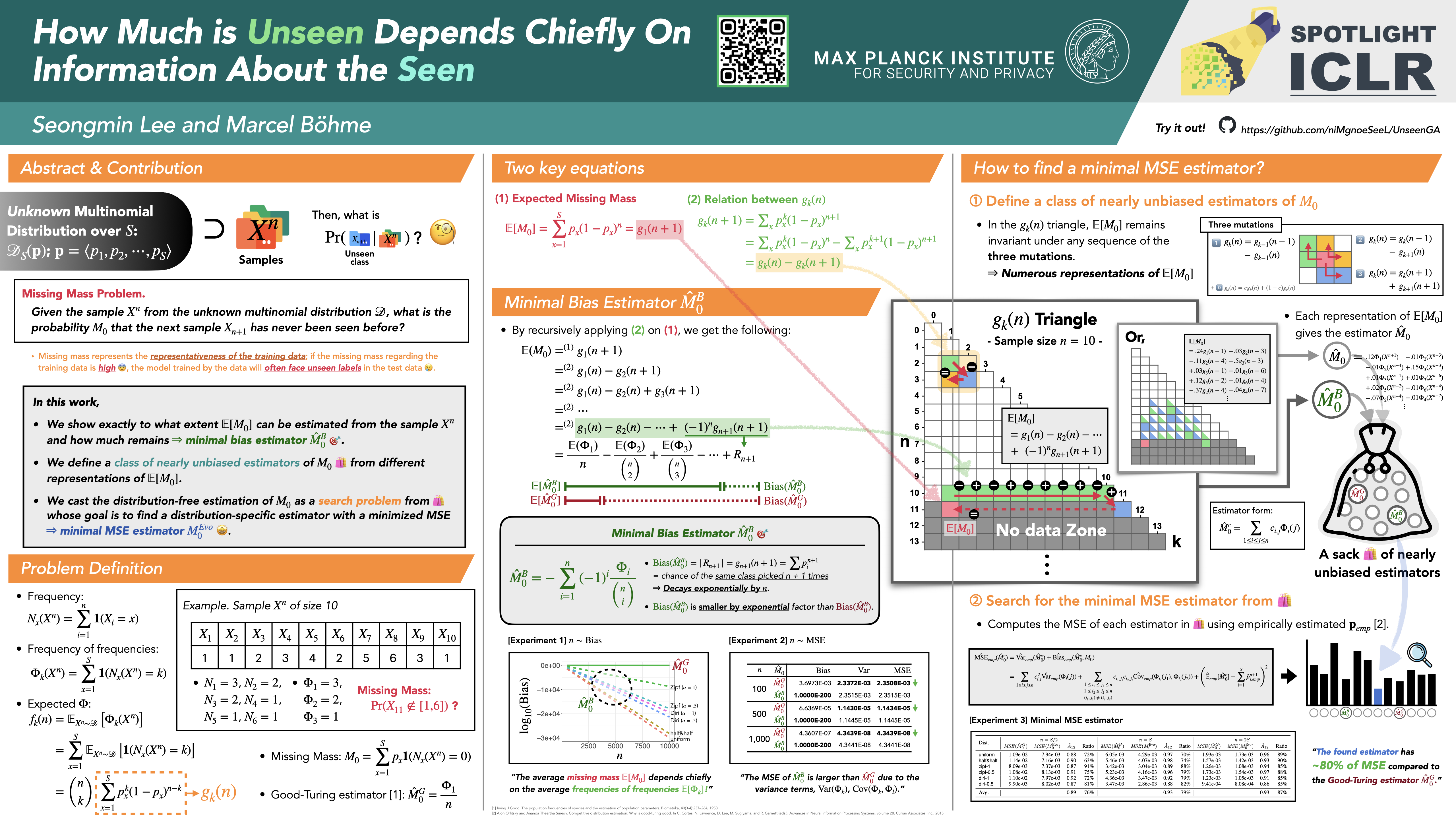
The *missing mass* refers to the proportion of data points in an *unknown* population of classifier inputs that belong to classes *not* present in the classifier's training data, which is assumed to be a random sample from that unknown population.We find that *in expectation* the missing mass is entirely determined by the number $f_k$ of classes that *do* appear in the training data the same number of times *and an exponentially decaying error*.While this is the first precise characterization of the expected missing mass in terms of the sample, the induced estimator suffers from an impractically high variance. However, our theory suggests a large search space of nearly unbiased estimators that can be searched effectively and efficiently. Hence, we cast distribution-free estimation as an optimization problem to find a distribution-specific estimator with a minimized mean-squared error (MSE), given only the sample.In our experiments, our search algorithm discovers estimators that have a substantially smaller MSE than the state-of-the-art Good-Turing estimator. This holds for over 93\% of runs when there are at least as many samples as classes. Our estimators' MSE is roughly 80\% of the Good-Turing estimator's.
Video
Chat is not available.
Successful Page Load