BAMDP Shaping: a Unified Framework for Intrinsic Motivation and Reward Shaping
{kind=link}
Abstract
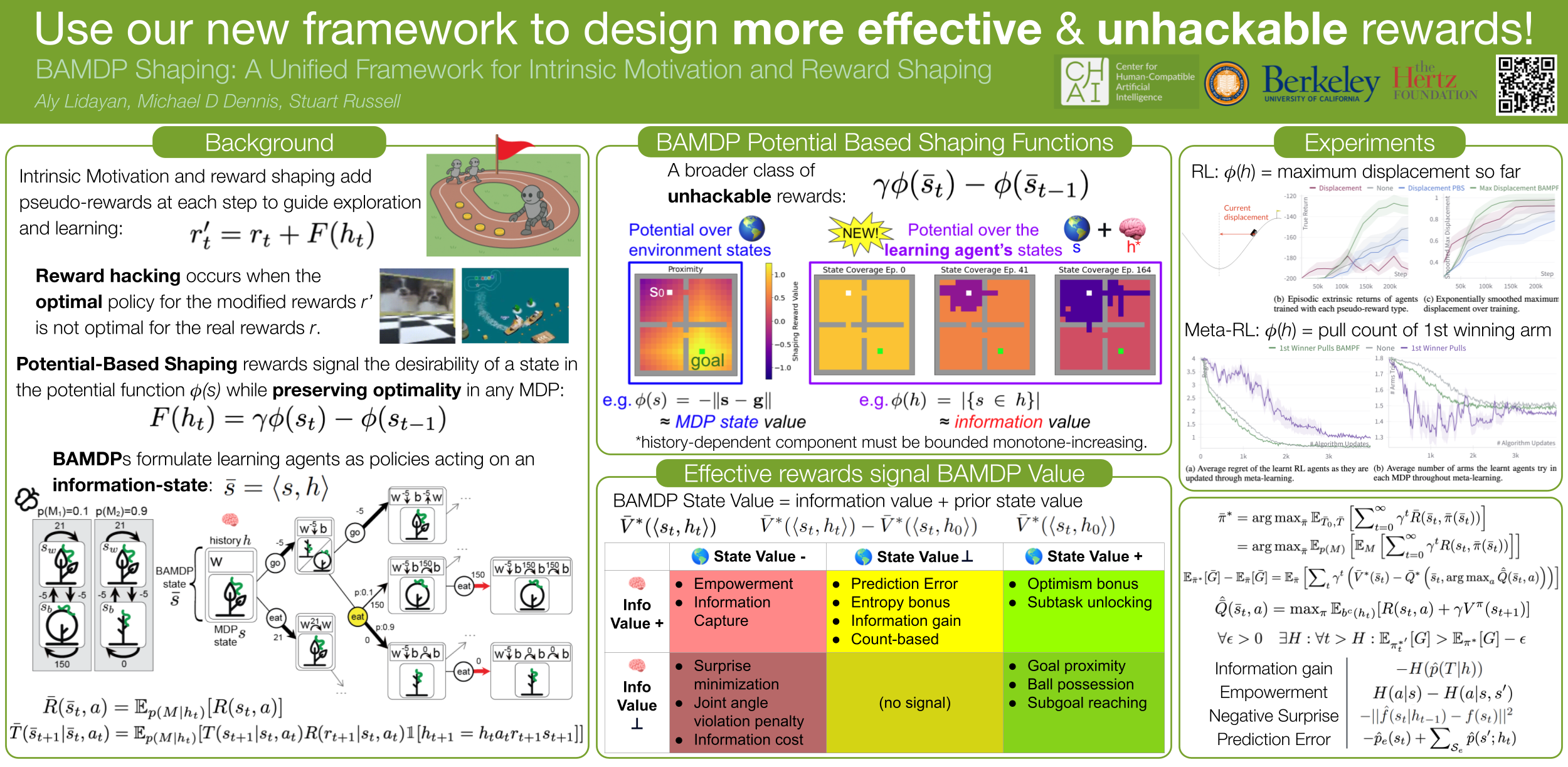
Intrinsic motivation and reward shaping guide reinforcement learning (RL) agents by adding pseudo-rewards, which can lead to useful emergent behaviors. However, they can also encourage counterproductive exploits, e.g., fixation with noisy TV screens. Here we provide a theoretical model which anticipates these behaviors, and provides broad criteria under which adverse effects can be bounded. We characterize all pseudo-rewards as reward shaping in Bayes-Adaptive Markov Decision Processes (BAMDPs), which formulates the problem of learning in MDPs as an MDP over the agent's knowledge. Optimal exploration maximizes BAMDP state value, which we decompose into the value of the information gathered and the prior value of the physical state. Psuedo-rewards guide RL agents by rewarding behavior that increases these value components, while they hinder exploration when they align poorly with the actual value. We extend potential-based shaping theory to prove BAMDP Potential-based shaping Functions (BAMPFs) are immune to reward-hacking (convergence to behaviors maximizing composite rewards to the detriment of real rewards) in meta-RL, and show empirically how a BAMPF helps a meta-RL agent learn optimal RL algorithms for a Bernoulli Bandit domain. We finally prove that BAMPFs with bounded monotone increasing potentials also resist reward-hacking in the regular RL setting. We show that it is straightforward to retrofit or design new pseudo-reward terms in this form, and provide an empirical demonstration in the Mountain Car environment.