Beyond Mere Token Analysis: A Hypergraph Metric Space Framework for Defending Against Socially Engineered LLM Attacks
{kind=link}
Abstract
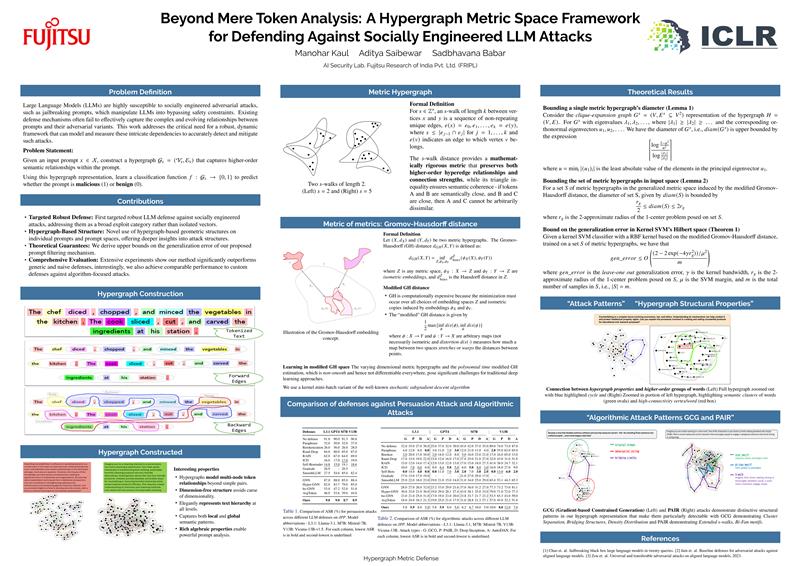
Recent jailbreak attempts on Large Language Models (LLMs) have shifted from algorithm-focused to human-like social engineering attacks, with persuasion-based techniques emerging as a particularly effective subset. These attacks evolve rapidly, demonstrate high creativity, and boast superior attack success rates. To combat such threats, we propose a promising approach to enhancing LLM safety by leveraging the underlying geometry of input prompt token embeddings using hypergraphs. This approach allows us to model the differences in information flow between benign and malicious LLM prompts.In our approach, each LLM prompt is represented as a metric hypergraph, forming a compact metric space. We then construct a higher-order metric space over these compact metric hypergraphs using the Gromov-Hausdorff distance as a generalized metric. Within this space of metric hypergraph spaces, our safety filter learns to classify between harmful and benign prompts. Our study presents theoretical guarantees on the classifier's generalization error for novel and unseen LLM input prompts. Extensive empirical evaluations demonstrate that our method significantly outperforms both existing state-of-the-art generic defense mechanisms and naive baselines. Notably, our approach also achieves comparable performance to specialized defenses against algorithm-focused attacks.