Forgetting Transformer: Softmax Attention with a Forget Gate
{kind=link}
Abstract
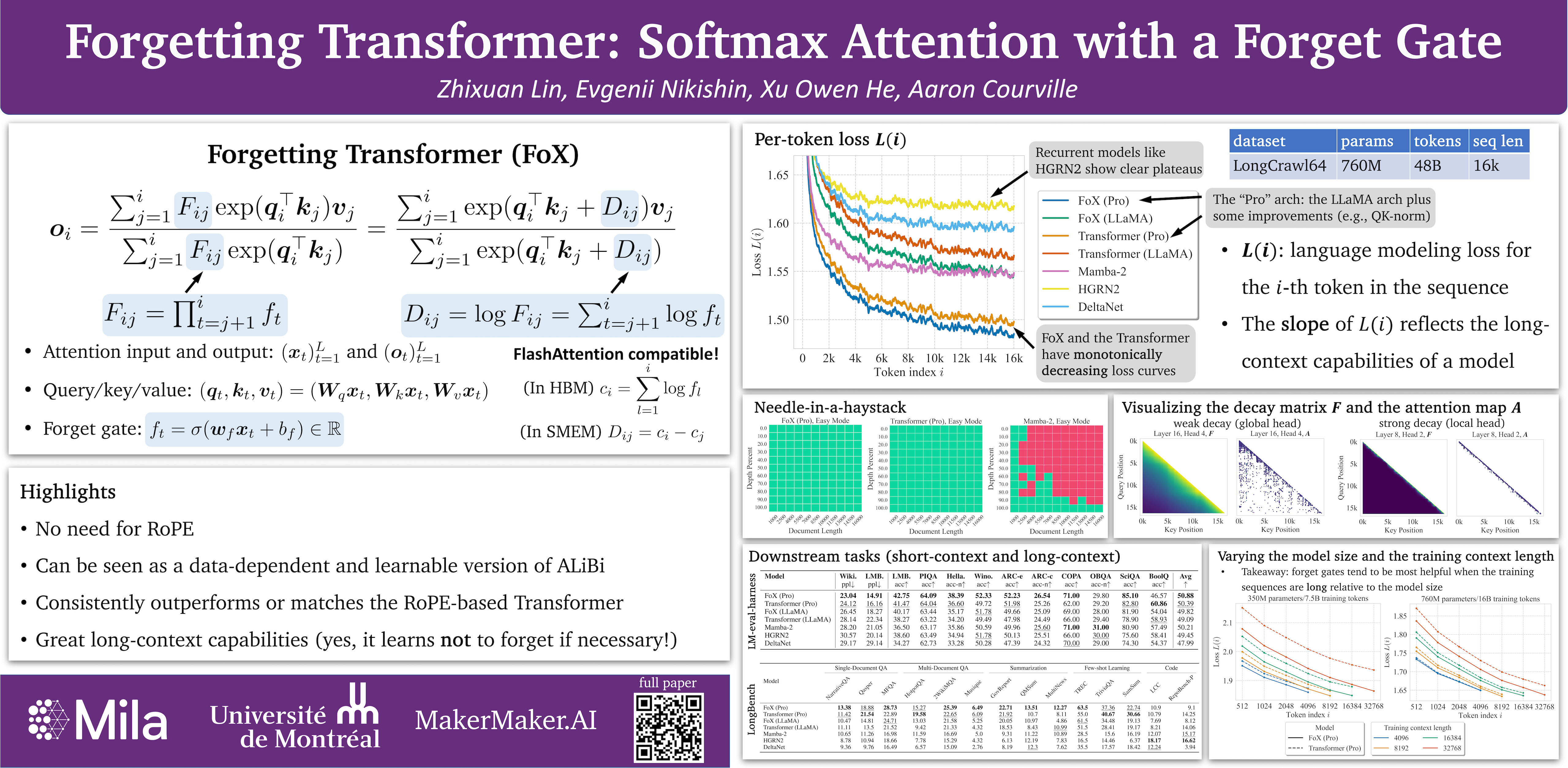
An essential component of modern recurrent sequence models is the forget gate. While Transformers do not have an explicit recurrent form, we show that a forget gate can be naturally incorporated into Transformers by down-weighting the unnormalized attention scores in a data-dependent way. We name this attention mechanism Forgetting Attention and the resulting model the Forgetting Transformer (FoX). We show that FoX outperforms the Transformer on long-context language modeling, length extrapolation, and short-context downstream tasks, while performing on par with the Transformer on long-context downstream tasks. Moreover, it is compatible with the FlashAttention algorithm and does not require any positional embeddings. Several analyses, including the needle-in-the-haystack test, show that FoX also retains the Transformer's superior long-context capabilities over recurrent sequence models such as Mamba-2, HGRN2, and DeltaNet. We also introduce a "Pro" block design that incorporates some common architectural components in recurrent sequence models and find it significantly improves the performance of both FoX and the Transformer.Our code is available at https://github.com/zhixuan-lin/forgetting-transformer.