Attribute-based Visual Reprogramming for Vision-Language Models
Chengyi Cai ⋅ Zesheng Ye ⋅ Lei Feng ⋅ Jianzhong Qi ⋅ Feng Liu
2025 Poster
{kind=link}
Abstract
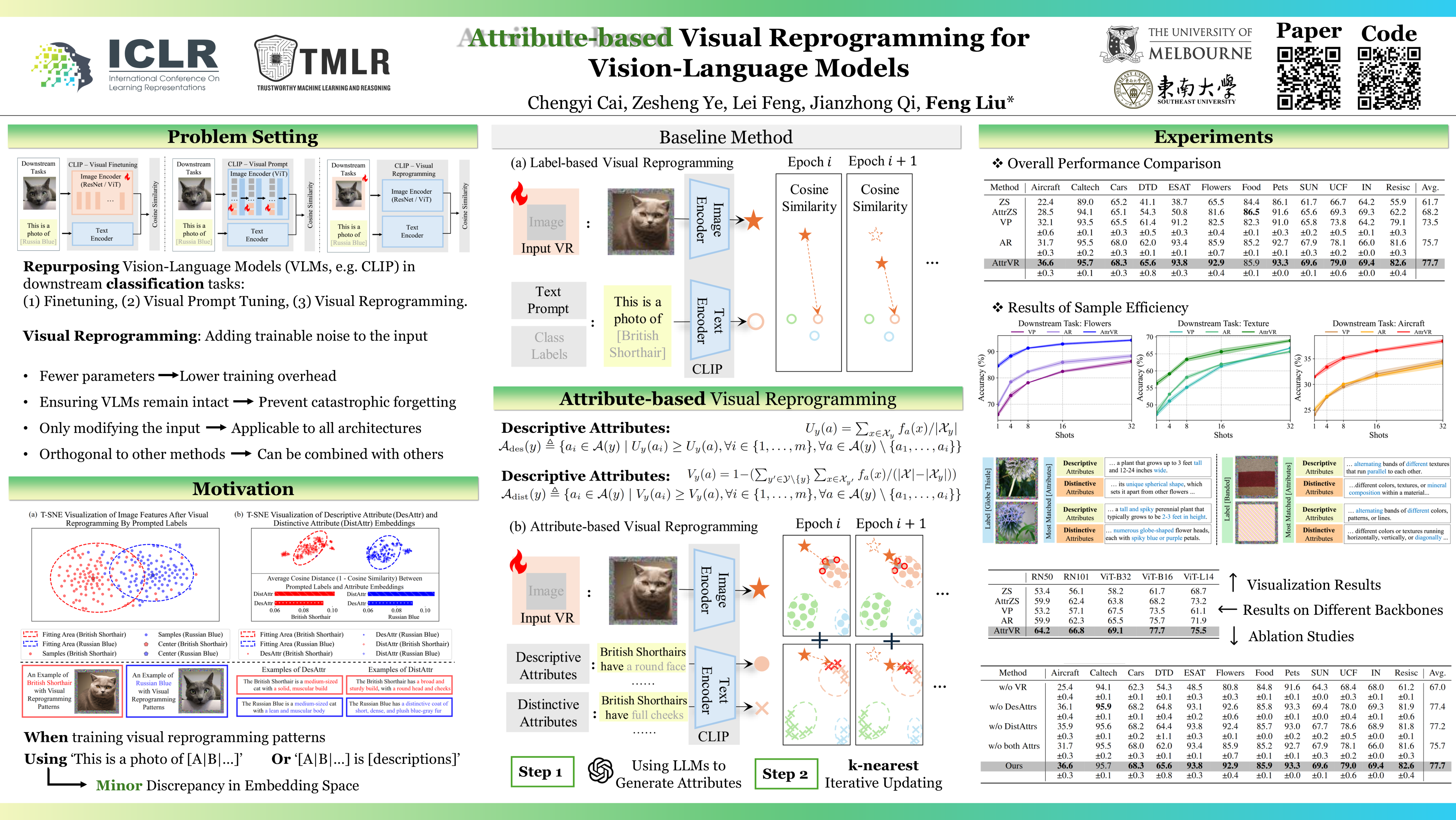
*Visual reprogramming* (VR) reuses pre-trained vision models for downstream image classification tasks by adding trainable noise patterns to inputs. When applied to vision-language models (e.g., CLIP), existing VR approaches follow the same pipeline used in vision models (e.g., ResNet, ViT), where ground-truth class labels are inserted into fixed text templates to guide the optimization of VR patterns. This label-based approach, however, overlooks the rich information and diverse attribute-guided textual representations that CLIP can exploit, which may lead to the misclassification of samples. In this paper, we propose ***Attr**ibute-based **V**isual **R**eprogramming* (AttrVR) for CLIP, utilizing ***des**criptive **attr**ibutes* (DesAttrs) and ***dist**inctive **attr**ibutes* (DistAttrs), which respectively represent common and unique feature descriptions for different classes. Besides, as images of the same class may reflect different attributes after VR, AttrVR iteratively refines patterns using the $k$-nearest DesAttrs and DistAttrs for each image sample, enabling more dynamic and sample-specific optimization. Theoretically, AttrVR is shown to reduce intra-class variance and increase inter-class separation. Empirically, it achieves superior performance in 12 downstream tasks for both ViT-based and ResNet-based CLIP. The success of AttrVR facilitates more effective integration of VR from unimodal vision models into vision-language models. Our code is available at https://github.com/tmlr-group/AttrVR.
Video
Chat is not available.
Successful Page Load