UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation
{kind=link}
Abstract
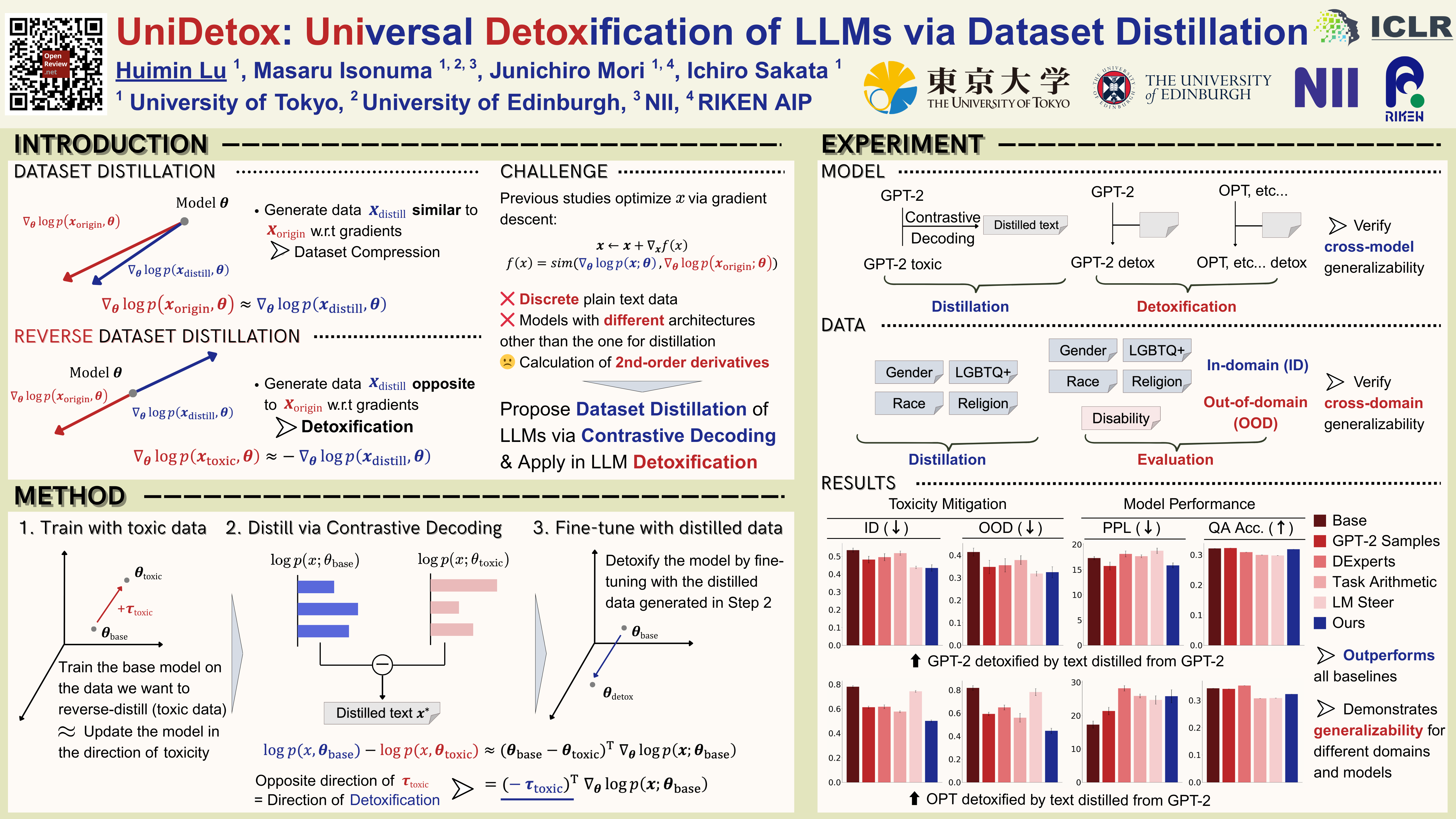
We present UniDetox, a universally applicable method designed to mitigate toxicity across various large language models (LLMs).Previous detoxification methods are typically model-specific, addressing only individual models or model families, and require careful hyperparameter tuning due to the trade-off between detoxification efficacy and language modeling performance. In contrast, UniDetox provides a detoxification technique that can be universally applied to a wide range of LLMs without the need for separate model-specific tuning. Specifically, we propose a novel and efficient dataset distillation technique for detoxification using contrastive decoding. This approach distills detoxifying representations in the form of synthetic text data, enabling universal detoxification of any LLM through fine-tuning with the distilled text. Our experiments demonstrate that the detoxifying text distilled from GPT-2 can effectively detoxify larger models, including OPT, Falcon, and LLaMA-2. Furthermore, UniDetox eliminates the need for separate hyperparameter tuning for each model, as a single hyperparameter configuration can be seamlessly applied across different models. Additionally, analysis of the detoxifying text reveals a reduction in politically biased content, providing insights into the attributes necessary for effective detoxification of LLMs.