TC-MoE: Augmenting Mixture of Experts with Ternary Expert Choice
{kind=link}
Abstract
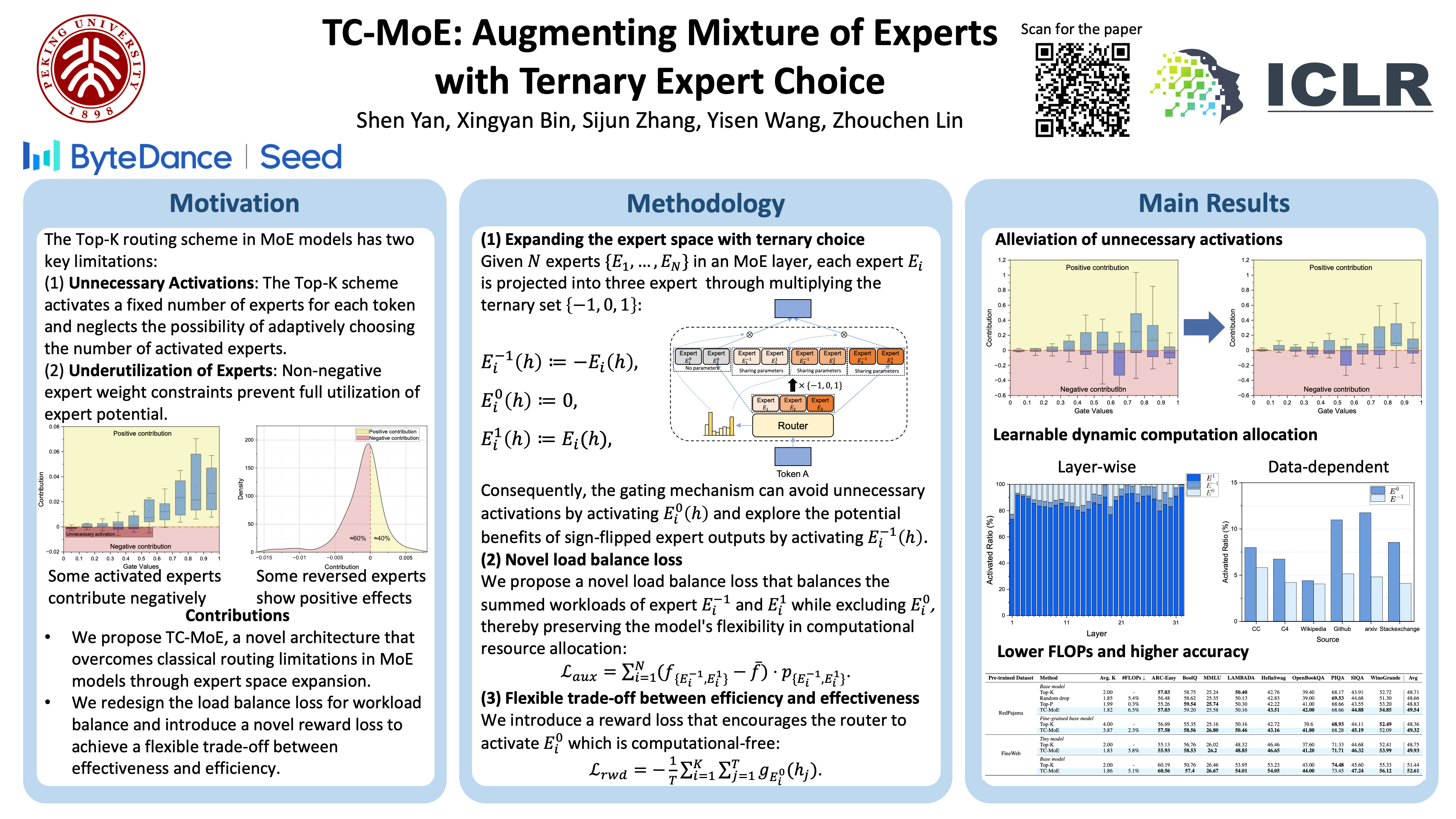
The Mixture of Experts (MoE) architecture has emerged as a promising solution to reduce computational overhead by selectively activating subsets of model parameters.The effectiveness of MoE models depends primarily on their routing mechanisms, with the widely adopted Top-K routing scheme used for activating experts.However, the Top-K scheme has notable limitations,including unnecessary activations and underutilization of experts.In this work, rather than modifying the routing mechanism as done in previous studies,we propose the Ternary Choice MoE (TC-MoE),a novel approach that expands the expert space by applying the ternary set {-1, 0, 1} to each expert.This expansion allows more efficient and effective expert activations without incurring significant computational costs.Additionally, given the unique characteristics of the expanded expert space,we introduce a new load balance loss and reward loss to ensure workload balance and achieve a flexible trade-off between effectiveness and efficiency.Extensive experiments demonstrate that TC-MoE achieves an average improvement of over 1.1% compared with traditional approaches,while reducing the average number of activated experts by up to 9%.These results confirm that TC-MoE effectively addresses the inefficiencies of conventional routing schemes,offering a more efficient and scalable solution for MoE-based large language models.Code and models are available at https://github.com/stiger1000/TC-MoE.