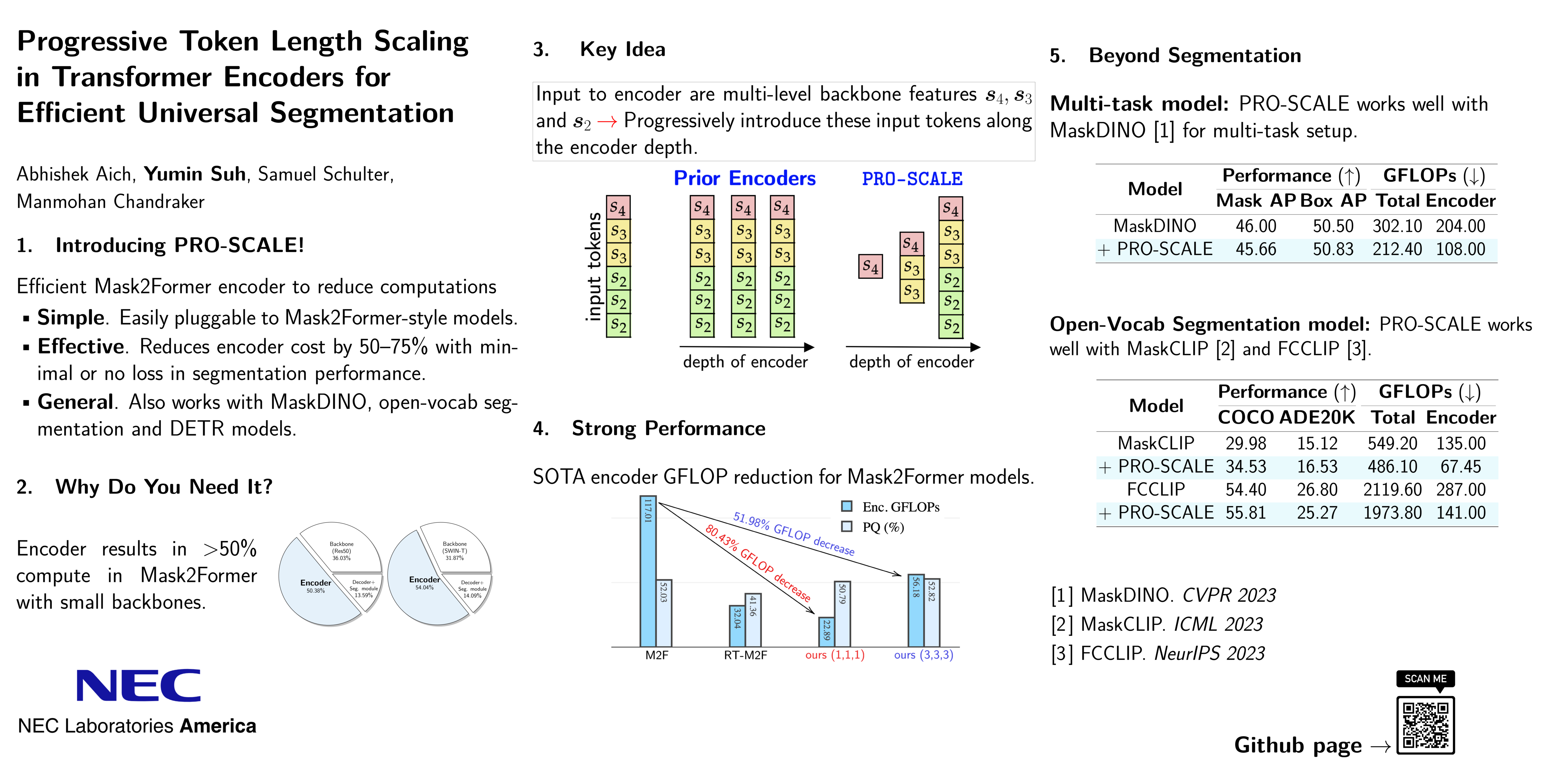
Progressive Token Length Scaling in Transformer Encoders for Efficient Universal Segmentation
{kind=link}
Abstract
A powerful architecture for universal segmentation relies on transformers that encode multi-scale image features and decode object queries into mask predictions. With efficiency being a high priority for scaling such models, we observed that the state-of-the-art method Mask2Former uses \~50% of its compute only on the transformer encoder. This is due to the retention of a full-length token-level representation of all backbone feature scales at each encoder layer. With this observation, we propose a strategy termed PROgressive Token Length SCALing for Efficient transformer encoders (PRO-SCALE) that can be plugged-in to the Mask2Former segmentation architecture to significantly reduce the computational cost. The underlying principle of PRO-SCALE is: progressively scale the length of the tokens with the layers of the encoder. This allows PRO-SCALE to reduce computations by a large margin with minimal sacrifice in performance (\~52% encoder and \~27% overall GFLOPs reduction with no drop in performance on COCO dataset). Experiments conducted on public benchmarks demonstrates PRO-SCALE's flexibility in architectural configurations, and exhibits potential for extension beyond the settings of segmentation tasks to encompass object detection. Code is available here: https://github.com/abhishekaich27/proscale-pytorch